



Convey Revs Up Memcached With Hybrid X86-FPGA Appliance

Convey Computer, a maker of hybrid computers that marry Xeon processors from Intel to field programmable gate array accelerators from Xilinx, has quite possibly come up with the killer app for its machines--boosting the performance of the Memcached caching software commonly used as a front-end for Web applications.
Memcached was created a decade ago by Danga Interactive to speed up an early social media site called LiveJournal. The software is a distributed Web cache that takes data – such as the elements of a Web page extracted from relational databases that sit behind a content management system – and puts it in the main memory of a server using a key-value store. When users request data as they surf a site, instead of hitting the back-end database server to compose the page on the fly from very slow disk drives in the database server, the Web server request for the page is directed to Memcached servers that have the page elements cached. A single Web page might have dozens of such elements, so performance here really matters.
Since Memcached runs out of main memory, it is fast compared to disk-backed database servers. It might take 10 milliseconds to grab page elements out of a database server but it takes under 1 millisecond to pull them out of Memcached, explains Bruce Toal, president and CEO at Convey, to EnterpriseTech. But Web sites want lightning fast, not just fast. We're talking sub-millisecond cache response times. As their users grow and their Web pages get more complex, companies have to put more and more Memcached servers behind their Web servers. The new Hybrid Core 2 Memcached appliance from Convey from is meant to solve this problem.
Of the top 20 sites on the Web, 17 of them use Memcached, including Facebook, Flickr, YouTube, Zynga, Slashdot, Twitter, and Wikipedia, just to name a few. And if you drill down into the stats, says Toal, about half of the top 5,000 sites on the Web have Memcached front-ending their databases, and untold public and private cloud providers use it as well. The largest Memcached site that Toal could identify has 30,000 servers running this caching software. This is, by any measure, a huge amount of iron.
Convey wants to help shrink the Memcached footprint at these data centers, and in its benchmark tests on its FPGA-goosed HC-2 systems, it has been able to demonstrate seven times the Memcached throughput, much lower latency (sub-millisecond, in fact, which is everything to a Web application), and a factor of three better bang for the buck on configured systems. (More on this in a moment.)
The HC-2 system links the FPGAs to the two-socket Intel servers not through the QuickPath Interconnect, as might seem obvious, but over the PCI-Express bus, which oddly enough is a much simpler and cleaner approach, according to Toal.
The early Hybrid Core-1 machines from Convey, which launched in late 2008, hooked the FPGAs directly into the Front Side Bus (FSB) of Intel Xeon chips and plugged them into the Xeon sockets themselves. The FPGAs were programmed with a "personality" that allowed it to accelerate particular kinds of functions, such as being a vector math unit or a random number generator for Xeons, which did not have these features at the time, or accelerating bits of software that are used to sequence proteins in life sciences applications. The plan had been to shift to the QPI links in future Xeons, but as it turned out, that link is not very friendly for coprocessing. Hooking FPGAs that have much lower clock speeds than Xeon CPUs onto the point-to-point interconnect slowed down all memory accesses on the system, which is not good for overall performance.
And so, Convey came up with a scheme to use the memory mapped I/O (MMIO) feature of the PCI-Express bus to maintain coherency between the main memory in the Xeon processor and the memory attached to the complex of FPGAs that accelerate workloads running on them. Toal says that the PCI-Express 2.0 x8 slots that are used to lash the FPGAs to the Xeons delivers performance that is on par with what QPI could do. It will get even faster when the FPGAs support PCI-Express 3.0 protocols, of course.
Interestingly, says Toal, moving the FPGAs outside of the Xeon processor sockets has enabled the HC-2 appliance to get more raw CPU processing power. This is important because the FPGA acceleration was so high on some workloads that the HC-1 machines were CPU, not FPGA, constrained. This is a much more balanced design.
There are three different models of the HC-2, as shown in the table below:
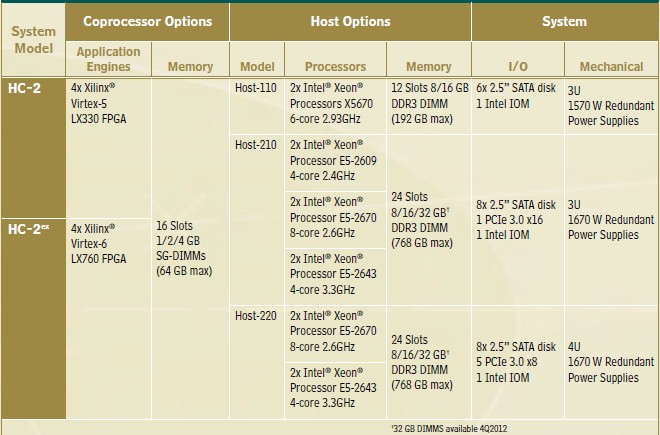
The servers come in 1U or 2U flavors, and the FPGA coprocessor unit is a 2U unit that snaps on top. The Xilinx FPGAs have from 16 GB to 64 GB of their own memory and have 80 GB/sec of bandwidth between the FPGAs and their memory. The machines can have up to 768 GB of main memory allocated to the CentOS variant of Red Hat Enterprise Linux and the Memcached 1.4.15 software that runs on it. Convey provides the tech support for this software as well as for the HC-2 appliance that it runs on.
Memcached was not an obvious workload to accelerate, but after analyzing it carefully, Convey realized that the parsing and hashing jobs inside of the caching software would lend itself to acceleration. Here is a diagram that shows conceptually how some of the Memcached work is offloaded to the FPGAs in the HC-2 machines:
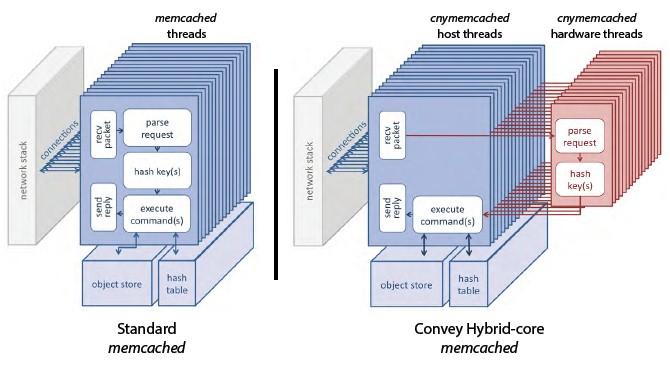
What Convey has done is move the blocks of the Memcached code relating to parse requests and hash key generation over to the FPGAs as a personality.
"For each thread in the host, we have a matching thread in the coprocessor. Parsing is very tedious and time consuming, and a very large percentage of what Memcached does is parsing. And parsing is also what is bad on an X86 processor. Parsing thrashes your branch prediction and out-of-order execution, so we put it on the coprocessor and you can do all of those branches in one clock, in parallel and you get the answer very, very fast."
The performance gains that Convey has been able to show with Memcached compared to a two-socket Xeon server are quite substantial, as you can see below:
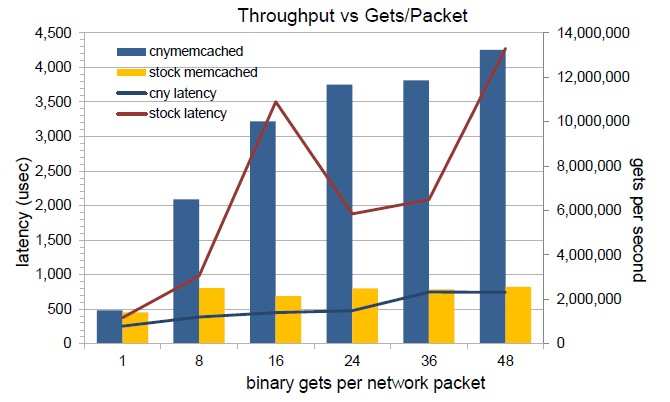
That's between three and seven times the performance at about one-fifth the latency, and as you can also see, the performance and latency are a bit more steady in the HC-2 appliance with the Memcached personality compared to the standalone Xeon server.
A base HC-2 Memcached appliance comes with two eight-core Xeon processors with 128 GB of main memory and four Xilinx LX330 FPGAs with 16 GB of their own memory; it costs $25,000. Based on the benchmark tests above, Toal reckons that this appliance can offer about three times the Memcached bang for the buck as a plain vanilla Xeon server with the same processor, and offer much lower latency to boot.






