



How Ancestry.com Branched Out And Embraced Scale

Ancestry.com is dedicated to discovering, preserving, and sharing family histories, and it knows all about the issues of scaling up IT operations to match a growing number of users. The company curates a progressively larger and richer set of data that describes who we are and how we relate, and this causes another set of scalability issues.
To make matters more difficult, but to also make the process of building larger family trees easier and in some cases possible in the first place, the company last year launched a new service, called AncestryDNA, that does pattern matching on DNA obtained from subscribers. This approach allows tree builders to try to find distant relatives even if they may not have detailed knowledge of their ancestors. This new service presented some of its own pesky scalability problems, which Ancestry.com solved by porting a genetics matching program that is at the heart of the AncestryDNA service from a single beefy server to a Hadoop cluster.
The Ancestry.com service has evolved considerably since it was first put on the Internet back in 1996.
"We do search, but we are not Google," Bill Yetman, senior director of engineering, commerce, and data analytics at the company, explains to EnterpriseTech. "We do sharing, but we are not Facebook. The goal is to add yourself, and your parents, and get back to something like the 1940 Census because then the system starts working for you. At that point, we will take the information that you have entered on your tree and we will start looking in our records and in other people's trees to try to find hints – it's a shaky leaf on the tree – to help you grow your tree. Hopefully, there is someone out there from one side of your family that already has a lot of information. It is sort of a crowd-sourced model. The key is we give you more hints, you accept more hints, and that is crunching through a lot of data to do it."
In a world where the perception is that all information is free and available over the Internet, Ancestry.com is able to charge $20 to $45 per month for subscriptions to its genealogy tools and the massive historical data sets that it has been able to procure, digitize, and index for searching. Ancestry.com has Census and user-generated family history data from the United States, several European countries, as well as Australia. This includes a total of 12 billion records and images. The company also owns Fold3P.com, which has more than 400 million military records, and Newspapers.com, which has archives of more than 1,800 US newspapers comprising more than 50 million pages. The idea is to link military documents and newspaper articles to your family tree as well as using these documents to help build it.

Bill Yetman, SVP of engineering, commerce, and data analytics at Ancestry.com
That Ancestry.com can charge for its services is, in and of itself, an accomplishment. That it can make money doing so and is growing would perhaps surprise many.
Ancestry.com has 2.7 million subscribers to its various services, with 2.1 million of them using the Ancestry.com genealogy service. That site adds about 2 million records and images per day and currently has more than 200 million photos, scanned documents, and written stories attached to the 55 million family trees in the system. All told, the system has more than 5 billion profiles of people who are living or have lived on Earth. (Some profiles have very little data, others have a lot more, of course.)
Back in 2007, when Ancestry.com first started offering DNA testing but had not yet turned it into a formal and integrated part of its genealogy service, the company generated $166 million in revenues and had only 800,000 subscribers. Ancestry.com went public in 2009, right in the belly of the Great Recession, but was taken private by several company executives and private equity firm Permira (which is the majority stakeholder) in 2012. In the last full year that it was a public company, Ancestry.com generated $400 million in revenues and $63 million in net income. Even though the company is privately held, Ancestry still talks about its business publicly, and in 2012 it brought in $487 million in sales. Because of charges relating to the privatization, net income took a hit, says a company spokesperson, but earnings before income taxes, depreciation, and adjustments actually rose a little faster than revenues and hit $179 million last year.
The AncestryDNA service, which was launched in May 2012, is driving some of the company's growth, which is made possible by the ever-falling price of sifting through DNA. The latest DNA kit costs $99 and does what is called an autosomal test, which means it looks at genetic material donated from both your mother and father that is contained in 22 of your 23 matched pairs of chromosomes. (The remaining chromosome determines if you are a man or a woman.) In this case, the DNA testing lab that Ancestry.com has partnered with looks at 700,000 single-nucleotide polymorphisms, or SNPs (pronounced "snips"). The sequence of A, T, G, and C nucleotides for those snippets of DNA comes to a little more than 2 GB of data, which the DNA sequencing lab that Ancestry.com uses uploads to its datacenter over secure FTP for each sample.
The autosomal DNA test can show you that you are related to someone else within a given probability, but it cannot tell you how you are related precisely. Yetman says that the test used for the AncestryDNA service can find fourth cousins to within a 90 percent probability, reaching back about 150 years.
The DNA approach is one way to get past roadblocks in building a family tree when you run out of historical data culled from family bibles, newspapers, government documents, and other people's family trees. Over 200,000 people have taken the DNA test so far and had their data about their DNA snips put into Ancetry.com databases. Over 10 million fourth cousin DNA matches have been identified in the system thus far. Genealogy is subject to network effects, like many other social phenomena, so as more people take the DNA test, the database will grow and the number of connections between people will grow even faster.
The Infrastructure Supporting The Growing Tree
As you might imagine, it takes a lot of infrastructure to serve up all of the data that Ancestry.com has gathered up over the past three decades. The company operates two data centers, one in Salt Lake City, Utah and the other in Denver, Colorado. They are not hot backups of each other yet, explains Deal Daly, senior director of technology operations at Ancestry.com, but that is part of the plan.
The core production systems at Ancestry.com have thousands of server nodes and over 10 PB of production data, with copies of data stored on auxiliary storage for safe keeping. The company uses a mix of relational database and Hadoop data storage for family tree and genetic data running on various clusters, and has other clusters to run its homegrown search engine, called Gravity and tuned specifically for the kinds of image and document data the company procures, and its hinting systems.
The Gravity search engine has over 4,000 nodes in total and is used as a front-end index to all of those billions of documents that have been scanned and indexed for fast access by Ancestry.com. Those curated documents are stored on Isilon disk arrays. (Isilon was acquired by EMC and its arrays are its scale-out NAS storage offering.) User-generated content, such as images and stories, is stored on BlueArc arrays that attach to the Gravity cluster. There is something on the order of 7.5 PB of total capacity dedicated the images and documents, according to Daly. The Gravity search engine is built from Dell PowerEdge R620 two-socket rack servers using Xeon processors. This search engine grows in direct proportion to the amount of new data added, and at 1 billion or so new records a year, that would be somewhere on the order of 10 percent growth in the node count. However, the company is figuring out ways to host more instances of its search engine components on a single machine – without resorting to full-blown server virtualization – and will be able to keep the server count down as the Gravity search engine needs to sift through more data for ever-larger numbers of subscribers.
Ancestry.com has been a Microsoft .NET shop for a long time and has used SQL Server for most of its databases with some MySQL databases also used for certain applications. Yetman says that the company has just switched to open source MySQL for all of its relational databases to cut costs. Importantly, MySQL offers database sharding techniques just like SQL Server did, which allows for databases to be broken up into pieces and spread around a cluster to boost the performance, scalability, and resiliency of those databases.
The family tree database has 33 shards and runs on a cluster of high-end ProLiant DL980 servers from Hewlett-Packard, which are backed by its 3PAR storage arrays. The MySQL database and application services behind that hinting feature of the Ancestry.com tree builder runs on a cluster of 40 PowerEdge R720 rack servers from Dell, which are a bit heftier than the PowerEdge R620s used in the search engine. All told, these two relational database applications have about 3 PB of production data.
Ancestry.com is pretty new to Hadoop, but the technology is very quickly becoming an integral part of the software stack. And the reason this is the case is precisely the reason Google invented MapReduce and the Google File System and why Yahoo! copied it to create Hadoop and the Hadoop Distributed File System in the first place. Ancestry.com had an application that could not scale, and its business is dependent on being able to scale up the service faster than the cost of delivering that service.
The typical brick-and-mortar shop spends somewhere between 1 and 3 percent of revenues on IT, and while Daly won't confirm what the IT budget is at Ancestry.com, he said it was towards the upper end of that range and certainly not as high as many would expect for an online business. Ancestry.com keeps the IT budge low with old-fashioned frugality and internal software development, among things.
Adopting Hadoop was part of that frugality as well as a necessity. Three years ago, Ancestry.com installed an experimental Hadoop cluster, based on the M7 distribution from MapR Technologies, to run machine learning algorithms against its family tree data. The company does not use the Mahout machine learning add-on for Hadoop, but rather another tool called Random Forests, an in particular one based on the Python language and hooking into the R statistical package. (Yetman says that this is what a couple of machine learning experts he hired from Yahoo! preferred to use, and hence Ancestry.com does.) Today, this experimental machine learning cluster has around 30 nodes and it is relatively stable, but will grow as data scientists play with larger and larger datasets.
The main Hadoop cluster, which is only about a year and a half old, is partitioned logically into two pieces to run very different workloads. Today, this main Hadoop cluster, which also runs the MapR Hadoop distro, has a total of 110 nodes and is expected to grow to around 200 nodes by the end of 2014. It will also have over 1 PB of storage across those nodes as this year comes to a close, estimates Yetman.
About 80 of the nodes on the main Hadoop cluster are used to support the DNA matching application, which is called Jermline. The remaining 30 nodes are used to do the traditional clickstream and user analysis as subscribers work on the Ancestry.com site, and this is what eventually feeds data into the predictive analytics of the machine learning algorithms on the experimental cluster.
"This is the year we really take hold and get our big data collected from the site and start analyzing it to move the company forward," says Yetman. "We will crunch that data and put it into a data warehouse and look at user engagement. We will be able to see what users are doing on the site, and we will try to see how that relates to customer retention and conversion and how we can help users be more successful."
Neither Daly nor Yetman are sure how these DNA matching and Web analytics workloads will grow in the coming months, but they have a good guess for the aggregate: More than double the compute in hopefully less than double footprints. Moore's Law will get more computing into each box, and therefore the company will be able to add fewer boxes even as the workload scales pretty fast.
This is the same story we heard talking to Cloudera and MapR recently about the typical cluster sizes and growth rates for beta and production Hadoop setups.
Hadoop was not in the plan back in 2007, when the DNA testing kits were first made available. In fact, Hadoop did not exist yet and it would be several years before Ancestry.com took the Germline application created by researchers at Columbia University, which was written in C++, to do DNA matching as part of its service.
The AncestryDNA service that launched in May 2012 quickly hit a wall because, as Yetman explains, Germline was never meant to be used in a production environment with thousands of DNA samples being tested concurrently. The code would only run on a single server, so Ancestry.com got the biggest, beefiest machines it could to do the matching. As the number of customers using the DNA kits increased, the number of samples to match increased, and very quickly the time to complete a matching run hopped onto an exponential curve:
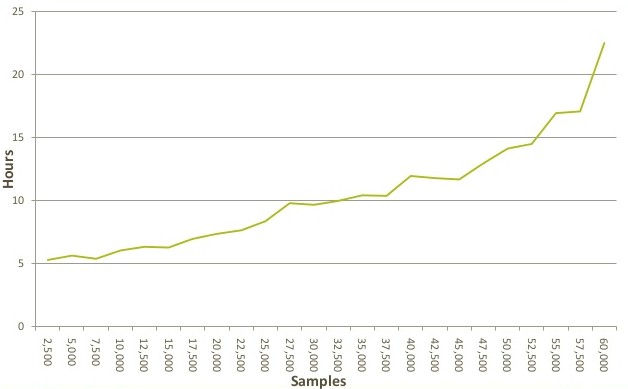
At somewhere around 60,000 DNA samples, it was taking nearly a day to run the program compared to five hours when there were only 2,500 DNA samples. Based on this curve and the expected performance of this Germline application, the techies at Ancestry.com predicted that it would take on the order of 300 hours to do a run at 100,000 samples in the DNA snippet database. The curve just got worse and worse and the DNA sample count rose.
After using Germline for a while, it hit a performance ceiling and Ancestry.com had to port it to Java and plunk it down onto Hadoop and the HBase database layer for HDFS to scale it up. This scalable version of the DNA sequence matching program is called Jermline and it will allow Ancestry.com to scale up that part of the business. Ancestry.com also rewrote the software so it could keep information from prior runs stored in the HBase database and just append new matches and the hashes that show them as they are created. (Germline threw the data away after each run, assuming you would be testing completely new batches of DNA each time.) Jermline does comparisons in batches of 1,000 people and each mapper in the cluster takes one chromosome from one person. The MapReduce matches DNA code snippets (called words) and updates the hash tables and then identifies segments of words that match. For each person, you add up the combined length of words that match and then run that length through another algorithm that predicts the probability of a cousin match. The longer the word length of aggregate matches, the higher the probability of being cousins.
Here is how the performance curve looks with Jermline running atop Hadoop and HBase:
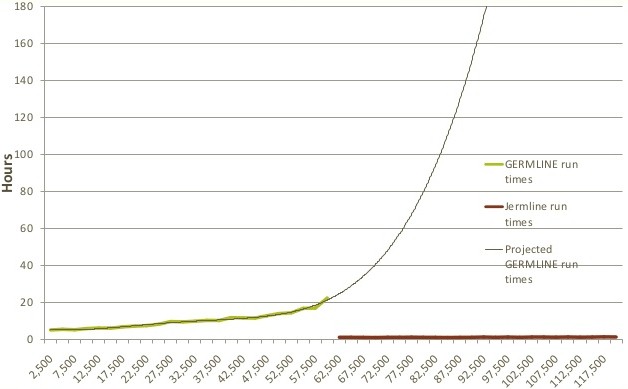
It is immediately obvious why Ancestry.com shifted from big beefy boxes to a parallel cluster to run this DNA matching job.
What is not obvious from the chart is that such performance improvements were not enough. Ancestry.com expects for the AncestryDNA service to take off and for its Hadoop analytics cluster to grow as well. Instead of going to either HP or Dell for servers for its Hadoop machines, the company went with Taiwanese contract manufacturer Quanta for dense-packed, bare-bones X86 machines with no vanity and lower prices.






