



Netflix Speeds Machine Learning With Amazon GPUs

Trying to figure out what 44 million of us in 41 different countries might want to watch next is not just a matter of guessing for video streaming service Netflix. It is a science, and the company wants to do a better job of it by deploying machine learning algorithms in the cloud and accelerating them with GPUs.
Netflix dumped its own IT infrastructure and went wholly to the Amazon Web Services cloud a few years back. So the software engineers at the company have no choice but to try to make its GPU-accelerated machine learning algorithms work on AWS. The engineers working on a prototype machine learning setup on AWS have shared the results of early tests and revealed the tools that they have deployed to turn it from a science project into an application.
Alex Chen, Justin Basilico, and Xavier Amatriain, like others in the machine learning field, stand on the shoulders of a lot of researchers who came before them. As often happens in recent years, Google researchers showed the way in a paper published in 2012, where it described a distributed machine learning framework it had created called DistBelief that spans thousands of machines, tens of thousands of cores, and train a network with billions of parameters. This research was done specifically because of the limitations of speeding up machine learning on GPUs, where organizations often have to limit the size of the datasets that the neural networks learn from because the latencies of bringing data across a cluster of machines makes the application too slow. Google tested a 1,000-node cluster with 16,000 cores, showing that you could distribute the machine learning across the cluster and get a significant speedup.
"While that was a remarkable milestone, the required infrastructure, cost, and computation time are still not practical," the Netflix researchers wrote in their blog.
Andrew Ng, working with fellow researchers at Stanford University and Nvidia, took another stab at accelerated machine learning last year with a GPU-accelerated systems, and showed that with three server nodes linked by an InfiniBand network, each with four Nvidia GTX680 graphics cards rated at around 1 teraflops each doing single-precision math. This relatively modest cluster was able to train a neural network with 1 billion parameters in a couple of days, and it could scale up to 11 billion parameters with sixteen such machines in a cluster.
Emboldened by these findings, Netflix got to work building a virtual cluster with CPUs and GPUs out on the AWS cloud. The company took a hybrid approach. Netflix wants to be able to train different models for different geographical regions of its customer base, and it also wants to train models based on a number of different parameters. These naturally fit into a single instance of a virtual server with one or two GPUs out on the Amazon cloud.
"The algorithm training itself can be distributed," the Netflix researchers explain." While this is also interesting, it comes at a cost. For example, training ANN [artificial neural network] is a comparatively communication-intensive process. Given that you are likely to have thousands of cores available in a single GPU instance, it is very convenient if you can squeeze the most out of that GPU and avoid getting into costly across-machine communication scenarios. This is because communication within a machine using memory is usually much faster than communication over a network."
To figure out what parameters to use for machine learning runs on each virtual node is an entirely different task, using a technique Netflix calls Bayesian hyperparameter optimization. Netflix could brute force it, setting up a net for each possible combination of parameters and seeing which one works best. But that is inefficient and time consuming. So Netflix has front-ended its virtual machine learning cluster with a tool called Spearmint that can find the best parameters and only run those through the machine algorithm. This part of the job runs on a CPU cluster, where it is well suited, says Netflix.
To get started, Netflix took a Lenovo S20 workstation with an Nvidia Quadro 600 graphics card with 98 cores and put a neural network on it. Training the neural network with 4 million samples took seven hours. Imagine their surprise when putting the same code on the cg1.4xlarge instance on AWS the training of the neural net actually took longer. This AWS instance has an Nvidia Tesla M2050 GPU with 448 cores and 3 GB of GDDR4 memory plugged into a machine that exposes 16 virtual cores and 33.5 GB of virtual memory to applications and has four 10 Gb/sec Ethernet ports. Despite this virtual setup having a lot more oomph than the Lenovo workstation, the neural network training took more than 20 hours to run.
As it turns out, the Nvidia Performance Primitive library, part of the CUDA development stack, took ten times as long to run on the Amazon cloud as on the workstation. After tweaking the way this library was called, Netflix was able to cut the training time down from 20 hours to 47 minutes on the Amazon slice and from 7 hours to two hours on the local workstation. The company also discovered that the neural net training could be sped up by disabling access to the PCI space in the Linux kernel. The Netflix engineers say that they can squeeze more performance out of the AWS cloudy GPU slices, perhaps by using a tool called Theano, a CPU and GPU math compiler written in Python, or by using kernel fusion techniques where CUDA kernels share data, thereby cutting down on memory transfers between the GPU cores and its GDDR memory.
The memory bandwidth issue on the GPU is a big deal for neural net training. The Tesla M2050 cards are rated at 148 GB/sec of memory, and Netflix is therefore interested in putting its machine learning algorithms on AWS g2.2xlarge instances, which have an Nvidia GRID K520 GPU, designed for visualization and virtual desktop work but having 1,536 cores that can nonetheless be used for computation. This K520 GPU has 198 GB/sec of memory bandwidth, and if Amazon could put in the GTX Titan video card, which it has not done, a GPU-enabled slice would have 2,688 cores delivering 4.5 teraflops of single-precision floating point math and 288 GB/sec of memory bandwidth. With some more tweaking, Netflix was able to get better performance on the G2 instance than on the CG1 instance, and would like to have an instance with a more powerful faster GPU and more memory bandwidth.
Having tuned up the neural network training on AWS instances, Netflix is now working on gluing together multiple instances, creating an application. Here's the basic shape of that application:
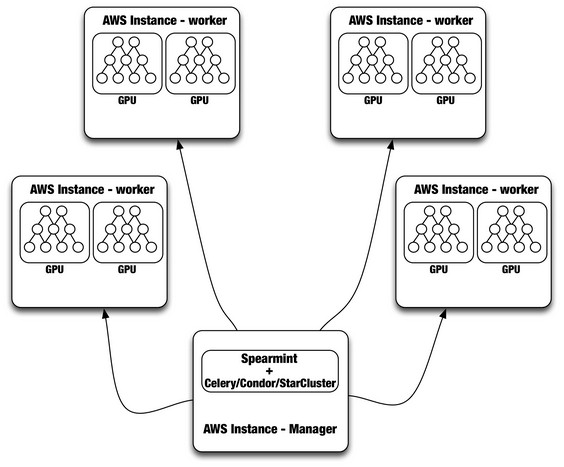
As you might expect, Netflix is keen on open source software. The initial setup includes the Celery distributed task queue, which manages the distributed hyperparameter tuning work that is dispatched out to the Spearmint program running on regular CPU instances on the Amazon cloud. Amazon says that the combination of Celery and Spearmint is working, it is examining using HTCondor out of the University of Wisconsin, or StarCluster, a variant of Grid Engine out of MIT, to manage the workflow across the AWS nodes.






