



How Facebook Compresses Its 300 PB Data Warehouse
When you have a 300 PB data warehouse running atop Hadoop, you do everything in your power to keep from adding another rack of disk drives to this beast. While social network giant Facebook is not afraid to throw a lot of hardware at a scalability problem, its software engineers are always looking for ways to make the infrastructure software that underpins Facebook more efficient and therefore require less hardware to get more capacity and performance.
Such is the case with a new compression algorithm that Facebook has cooked up for its data warehouse, called ORCFile, which runs atop the Hive relational layer on the data warehouse, which uses the Hadoop Distributed File System to store all kinds of log information from the site. Facebook has made some tweaks to an earlier version of the program, called RCFile, that allows for data compression to compact files by a factor of 8X over raw HDFS formats, compared to about 5X compression using RCFile.
The analytics engine at Facebook is enormous. The company has north of 100,000 servers running in its four datacenters, and as Ken Rudin, head of analytics at Facebook, explained to EnterpriseTech last fall, the analytics engine and the advertising operations at the company run atop tens of thousands of server nodes – a significant portion of the entire server infrastructure at the company. Facebook has its own modified version of Hadoop, which spans clusters that are geographically distributed. This Hadoop cluster has 300 PB of aggregate data, and the company is adding about 600 TB of data per day to it. To put that in perspective for you, that is a new rack of storage servers every three days or so. This is obviously not sustainable.
The company runs MapReduce batch jobs atop this data warehouse, of course, and created the Hive relational layer because it wanted something that looked and felt more like a SQL-driven relational database to run queries against the data stored in HDFS. Hive hooks into MapReduce. The massive data warehouse is also tickled by Presto, a SQL query engine that bypasses MapReduce and can run queries against HDFS directly. Facebook open sourced Presto last fall, just like it did Hive and the original RCFile compression for Hive data and the new ORCFile method it is talking about now. That means the techniques that Facebook's software engineers have come up with to improve compression on its data warehouse are available to all Hadoop users, and possibly for other stores that put data in columnar formats.
Facebook software engineers Pamela Vagata and Kevin Wilfong announced the new ORCFile compression technique in a blog post, and also offered up an in-depth technical discussion of how it works and what performance the new method delivered for Hive tables. As with other columnar storage formats, the original Record-Columnar File (RCFile) format created by Facebook, breaks data into row groups and then stacks them up into columnar chunks inside of HDFS blocks. Each column of data is written to the disk drives in the Hadoop cluster using a data compression algorithm such as Zlib or Lzo. When queries run against the data, the sniff into the metadata that describes each compressed chunk and only open and decompress the part of the columnar datastore that are necessary for that particular query, which boosts performance. On average across the Facebook datasets, RCFile provided about a 5:1 compression ratio, which is arguably pretty good. But when you are adding a rack of drives every three days, you have to do better.
Hadoop distributor HortonWorks was already working on the problem with its ORCFile alternative for Hive, announced last year. Here are the compression ratios that HortonWorks was able to see with various compression and data store methods for Hive using a TPC-DS data warehousing dataset:

ORCFile is part of the "Stinger" project at HortonWorks to boost the performance of queries in Hive by a factor of 100X. As you can see, on this dataset, HortonWorks was getting about a 4.5X compression ratio on the ORCFile embedded in Hive 12 compared to plain vanilla text encoding. Facebook did not see such a radical jump in its own data with ORCFile, and so it made some modifications.
With ORCFile, data is written to disk in 256 MB stripes, which are similar to the row groups in the RCFile encoding, but there are other layers of encoding and metadata to make data skipping work better and to boost the performance. However, on Facebook's data, ORCFile caused some Hive tables to bloat up while others compressed well, and the average was not much of an improvement. String data makes up about 80 percent of the columns in the data warehouse at Facebook, so the software engineers took apart ORCFile and make some tweaks to it, and they also only employed a method called dictionary encoding to the stripe when it was beneficial rather than solely as the original ORCFile did. Facebook made a lot of changes deep down in the code, which you may or may not be interested in, but anyone running Hive at scale should be interested in the results. Here is the effect on query performance with the three different versions of RCFile:
 And here is the effect on write times across all queries running on the Facebook data warehouse:
And here is the effect on write times across all queries running on the Facebook data warehouse:
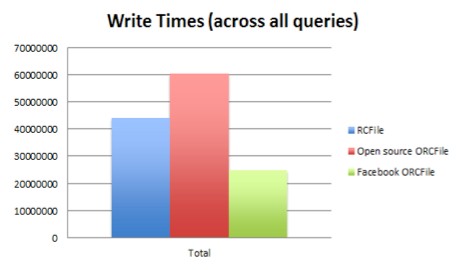
To sum it all up, the modified ORCFile format compresses Facebook's data by a factor of 8X over the raw text format, which is about 63 percent better than the prior RCFile method. The ORCFile writer is three times faster than the open source variant from HortonWorks, and many queries run as much as 3X faster.
Looking ahead, Facebook is looking at a number of other areas to improve the modified ORCFile tool.
"These ideas include supporting additional codecs such as LZ4HC, using different codecs and compression levels for different columns when encoded differently, storing additional statistics and exposing these to query engines, and pulling in work from open source such as predicate pushdown," the software engineers write in the blog. "We also have several other ideas to further improve storage efficiency for our warehouse. This includes eliminating logical redundancies across source and derived tables, sampling for cold data sets, and augmenting the Hive type system with additional commonly needed types that are currently stored as strings."
Thus far, Facebook has rolled this modified ORCFile compression onto tens of petabytes of tables its capacity in the data warehouse, and it has reclaimed tens of petabytes of storage. This is about as close to free money as a hyperscale datacenter operator can get. Looking ahead, the company is looking at the possibility of adding different codecs to the tool and allowing different codecs to be used for compression and decompression on different parts of the data warehouse, depending on what method is best.
The modified ORCFile software is open source and available on GitHub.






