



Google Runs All Software In Containers
The overhead of full-on server virtualization is too much for a lot of hyperscale datacenter operators as well as their peers (some might say rivals) in the supercomputing arena. But the ease of management and resource allocation control that comes from virtualization are hard to resist and this has fomented a third option between bare metal and server virtualization. It is called containerization and Google recently gave a glimpse into how it is using containers at scale on its internal infrastructure as well as on its public cloud.
We are talking about billions of containers being fired up a week here, just so you get a sense of the scale.
Google, of course, is often at the front-end of technology transitions, mainly because operating at its scale requires it to be. Google breaks things before most companies hit a performance or scalability limit and the efficiency of its computing and datacenters determine its profit margins moreso than a typical Fortune 500 or Global 2000 company and hence this relentless pursuit of efficiency in the datacenter.
In a talk at the GlueCon 2014 conference last week in Denver, which covered all kinds of modern infrastructure issues, Joe Beda, a senior staff software engineer for Google Cloud Platform, the public cloud arm of the search engine giant, talked about the company's decade-long effort to create a more lightweight virtualization layer and how it is deployed internally on Google's infrastructure.
Beda was not specific about what different types and levels of containers Google uses in its massive infrastructure (with well over 1 million servers scattered around the globe) but he did say that "everything at Google runs in a container" and that "we start over 2 billion containers per week."
Google didn't say how many containers it retires per week. Presumably this is also a large number as workloads shift around.
That Google runs virtualized servers may come as something of a surprise to those who assume that the company runs most of its back-end software, as well as the minimalist front ends we see as we consume its services online, atop bare metal. But here is how it works. Google fires up its homegrown servers, lays down a set of containers, and then either runs the applications on top of these containers or, if it needs to run operating systems and applications not directly supported by its containers (such as FreeBSD or Windows Server on the Compute Engine public cloud), then it lays down a KVM hypervisor and fires up VMs on that. The whole shebang hooks into Google's Omega job scheduler, presumably. (We have sent our questions off to the search engine giant about how the job scheduler hooks into the containers and await a response.)
Here is what the container stack looks like at Google, conceptually:

Google has been on a mission to come up with ways to isolate workloads from each other on shared hardware for the past decade.
The company came up with some limited isolation for its Linux-based systems back in 2004 and two years later Google cooked up something called control groups, shortened to cgroups, as a Linux kernel extension that allowed for the control of allocation of resources for single processes on systems all the way up to various kinds of containers on Linux. The cgroups code was also created to allow for checkpointing of processes so they could be recovered, to set priorities for resources for code, and to measure what processes in software were consuming specific resources for chargeback. Google uses cgroups as the underlying container virtualization layer and layers KVM on top of that when it needs to run an operating system other than the raw cgroups variant of Linux it has.
The cgroups code has been merged into the Linux kernel and is the basis for the Linux containers (LXC) that is now being commercialized in the latest Linux releases from Red Hat, SUSE Linux, Canonical, and others. They are distinct, however. Just like lmctfy and Docker, another Linux container technology, are different.
Containerization is not a new concept, and in fact, it is arguably the oldest concept in server virtualization. Modern virtualization software using what is called a type 1 or bare metal hypervisor throws down a layer of software that provides complete isolation for virtual machines or logical partitions (the names are different, the ideas are the same) that in turn run whole copies of the operating system. With containers, rather than create whole machines with their own operating systems, a sandbox is created that runs atop a shared operating system kernel and file system that looks and feels like a complete, isolated instance of the operating system – from the point of view of applications and security settings – even though it is not. Mainframes, proprietary minicomputers, Unix machines, and eventually X86 systems running Windows, Linux, and Solaris had containers as well as hypervisors and there are many variations on the theme.
Google came up with its own variant of LXC containers, which it calls lmctfy and which it launched in 2013. The software's name stands for Let Me Contain That For You and is currently in beta at the 0.5.0 release level; it is open source software so you can play around with it as you see fit. While cgroups and LXC are a little bit complex to manage, lmctfy containers are supposed to be easier to manage and to hook into job schedulers running on clusters of machines. Lmctfy has two layers, called CL1, which currently provides CPU and memory capacity isolation in an application container, and CL2, which is a Linux daemon that sets the policies and enforces them for the CL1 layer. CL2 is still in development.
At the moment, lmctfy does not allow for the overcommitment of resources, a common feature in bare metal hypervisors that helps to drive up utilization on systems. Over time, the CL1 layer will provide for disk and network isolation, support for root file systems and the importing and exporting of disk images based on those root file systems, and checkpoint and restore on containers. The CL2 daemon controls the fair sharing of resources on a machine and will eventually be updated with code to set quality of service levels and enforce them as well as monitoring the containers and extracting statistics from them for job schedulers. Google has tested lmctfy on the Ubuntu Server 3.3 and 3.8 kernels but says it will work on others.
Interestingly, Beda said that Google does have overcommitment features for its internal infrastructure but not for its Compute Engine public cloud.
The main thing about lmctfy is that it separates the container policies from the enforcement of those policies, which is an engineering approach that Google takes again and again in the hyperscale systems it designs. (The centralized, hierarchical approach was demonstrated again back in April when Google revealed the inner workings of its "Andromeda" virtual networking.)
Google's lmctfy is designed to be a replacement for the standard LXC being embedded in Linux distributions these days. Google did not like the fact that LXC does not have an abstraction of all of its interfaces into the Linux kernel and that it did not have a set of APIs that will manage LXC programmatically.
Like LXC containers, lmctfy will integrate with Docker, which is another container technology that also includes an application repository and change management system. Docker was started by cloud computing provider dinCloud and that was recently adopted as an alternative on top of Amazon Web Services. Both Docker and lmctfy allow for full root file systems to be installed in each container. (Many containers do not do this.) Docker is still in beta, just like lmctfy, and has been added to the recent Ubuntu Server 14.04 LTS from Canonical and the forthcoming Enterprise Linux 7 from Red Hat.
Aside from describing Google's use of software containers in its infrastructure, Beda told the group attending GlueCon 2014 that the company would eventually support containers on the Google Cloud Platform and that it would be integrating with Docker to monitor, start, and kill containers on server nodes. Google has open sourced the container agent for Cloud Platform, which you can see here. Here is what the stack looks like conceptually:
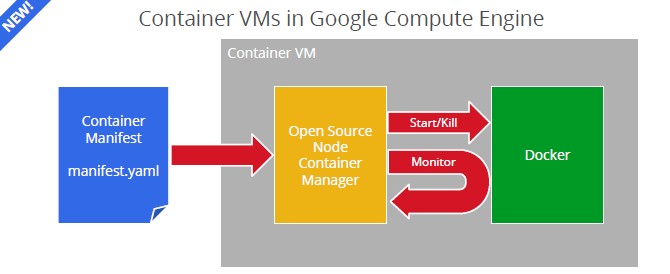
The way Google has set this up, there is a container manifest that is a declarative description of a set of containers and the resources they need to run. An imperative set of instructions, Beda explained, would say something like start this container on that particular physical server, but the container manifest will work more broadly and in a declarative manner and instruct the infrastructure to, for instance, run 100 copies of a container and maintain a certain level of availability in those containers for their tasks. (This is why the means in which Google is linking lmctfy and Docker into its Omega scheduler is important to understand.) Interestingly, a container manifest is an all or nothing proposition--all containers on a host machine have a shared fate, and if one goes down, they all go down. Scheduling is done at a node level. The reference node container manager starts up the containers and tries to keep them running when there are failures and in the future Google will be adding the capability to dynamically change the container manifests and will expose logs, history, and other metrics.
On top of Compute Engine infrastructure cloud and the Managed VMs in the App Engine platform cloud, Google will also be creating preloaded software images that include Docker and the Node Container Manager and that will load the container manifest at load time.
"The support we are talking about now includes the workload running in a cgroup/container in a VM hosted on GCE," Beda explained in an email to EnterpriseTech. "That VM on GCE is running on KVM/cgroups under the covers; cgroups are pretty lightweight. The main thrust for cgroups, traditionally, for Google is around resource isolation and performance predictability so that we can get more out of physical machines. For most customers, the value prop for Docker is around packaging and portability."
It will be interesting to see if this approach will be mimicked by the hyperscale community as so many other technologies created by Google have been.






