



In-Memory Boosts Oracle OLTP By 2X, Analytics By 1000X
With the lion's share of the relational database market underpinning the systems of record humming along in datacenters, Oracle cannot afford to let its rivals get too far ahead of it when it comes to in-memory processing. After years of development and three and a half months of beta testing, Oracle is nearly ready to ship the in-memory features of its new 12c database.
Oracle co-founder and CEO Larry Ellison hosted a coming out party for the In-Memory Database option for Oracle 12c and as usual, he likes to put on a show. This one featured a bunch of demonstrations of query processing on single node Exalytics and multimode Exadata clusters as well as on the Sparc M6-32 NUMA machine, all aimed at showing how much faster Oracle 12c is with the in-memory option and also explaining how Oracle's approach is different from SAP with its HANA in-memory database. Ellison also showed the speedup customers are seeing running various Oracle applications.
Oracle previewed the 12c in-memory database technologies last September during its OpenWorld conference, along with the launch of its top-end Sparc M6-32 systems, which have 32 sockets and support 32 TB of main memory. Regular relational databases store data in rows and index them for fast searching and online transaction processing. More modern databases, including the Exadata storage servers that underpin the engineered system clusters from Oracle by that same name, have a columnar data store to which is added data compression. The end result, coupled with high-speed networking between nodes and flash to accelerate data movement, is to radically speed up analytics pre-processing that is then fed up to the database.
With the In-Memory Database option, Oracle has done a bunch of very clever things. First, Oracle is now storing data in both row and column format – at the same time – and updating each to maintain transactional consistence across the formats. This puts overhead on the database management system. But Oracle has cut out a bunch of overhead by adding the columnar store in-memory for a subset of the hottest database information. In a typical database, there are a few indexes against that database to speed up transaction processing and then perhaps another ten or twenty other indexes that are designed to speed up analytical processing. Every time a row is updated with information or a new row is inserted into the database, all of those indexes have to be updated. This, as it turns out, takes a lot of compute effort and time. With the 12c in-memory option, analytical queries are meant to be run against the columnar store in the main memory of the machine, so Oracle did something simple: it threw out all of the analytical indexes. The columnar data is not logged or indexed either, and columns, partitions, or whole tables are put into memory and compressed, and the lack of logging and indexing means that queries against the in-memory store run faster than you might expect.

The net result is that analytical queries against the columnar store portion of the Oracle 12c database run one, two, and sometimes three orders of magnitude faster than they did with the traditional row store of the database with multiple indexes to speed up queries. And, importantly, online transaction processing workloads run about twice as fast, too.
This last bit is important. "We have a lot of customers that use our database for transaction processing, so we cannot compromise transaction processing," explained Ellison. And indeed, the design goals for the in-memory option for the Oracle database was to boost analytics queries against a production OLTP database or a data warehouse by at least 100X, to boost OLTP itself by a factor of 2X (by allowing for rows to be inserted anywhere from 3X to 4X faster), and to do this with no application changes. Oracle had other goals, including the fact that it has to run on all existing hardware where Oracle 12c is supported, not on specialized configurations of systems that are sold as appliances, and that customers should be able to turn it on with a flip of a switch after setting a few parameters.
The row format of the 12c database remains unchanged except for the elimination of the analytics indexes, and the columnar store allows data to be compressed by anywhere from a factor of 10X to 20X among early adopters.
"We get a lot more data into memory than you might think possible," said Ellison.
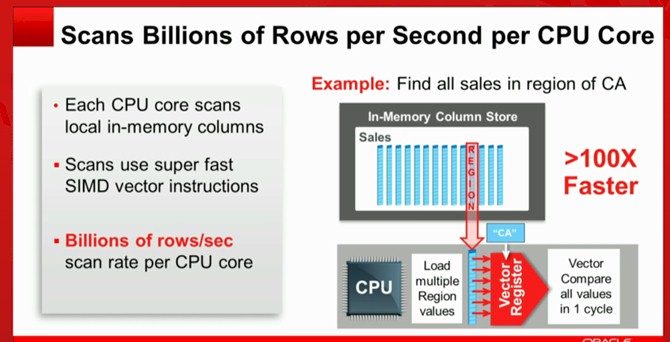
And thanks to using the vector instructions commonly added to processors these days, a single CPU core in a system can scan 2 to 3 billion rows per second of data. As you add cores to the system, the scans are done in parallel and speed up by that multiple, more or less. Or, you can scan that much more data in the same time – however you want to use the compute capacity. Table joins are converted into fast column scans as well and run about 10X faster in the columnar format in main memory.
For the persistent, row-formatted data, it can be stored across memory, flash, and disk. Unlike SAP HANA, where all of the data has to be stored in memory, Oracle can put the hottest row-formatted data in a portion of the system memory and warm data on flash and cold data on disks. (IBM's BLU Accelerator in-memory option for its DB2 database for Linux, Windows, and Unix platforms similarly does not require all of the data to be resident in memory for the in-memory acceleration to work.) The upshot, said Ellison, is that for each tier in the system, you have specialized algorithms and compression, mixing in-memory speed with low-cost disk for persistent storage. In an Exadata system, you get the speed of the main memory, the I/O operations per second of flash, the low-cost of disk, and the scale-out capabilities of the Exadata platform.
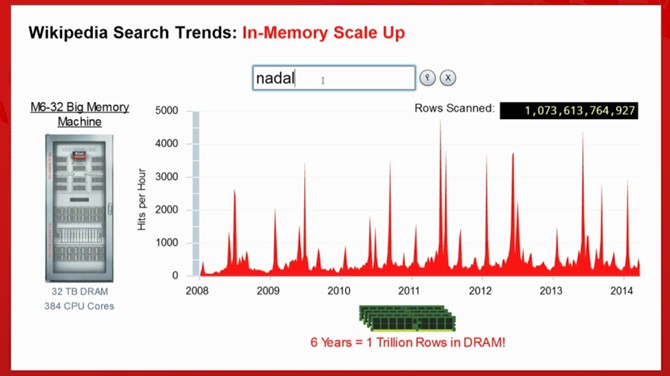
If you really want to run queries fast, Oracle suggests the Sparc M6-32 system, which has 384 cores, 32 TB of main memory, and memory bandwidth across the "Bixby" NUMA interconnect of 3 TB/sec. (That interconnect scales up to 96 sockets and 96 TB of memory, although Oracle has not delivered such a system as yet.) Oracle demonstrated an M6-32 system querying over 1 trillion rows in the blink of an eye at the 12c in-memory option launch.
Ellison joked that some queries created by financial services giant JPMorgan Chase were put to the test on the new 12c database with the in-memory columnar store turned on, and that the executives at the bank just laughed. Not because the queries were sped up by an order of magnitude, but that they finished at all--they had run for months without ever completing.
For tough cases, where the queries are complex and the data is as well, analytics queries ran only 10X to 15X faster, but in many cases among early adopters, the speedups were remarkable. One unnamed car manufacturer cited by Ellison using the cost management modules in Oracle's E-Business Suite had a query for optimizing costs for production of vehicles, shown below:

In many cases, where the datasets were smaller and the queries less complex than the manufacturing bill of materials optimization routine shown above, queries that took hours to minutes to complete on the row-formatted databases running on disks were able to finish in seconds or even in under one second using the columnar in-memory store. More than three orders of magnitude better response time on queries.
The in-memory option for Oracle's 12c database will be available in July. Pricing has not was not set yet, but Tim Shetler, vice president of product management at Oracle, tells EnterpriseTech that it will have an add-on price to the core 12c database, much as the Real Application Clusters (RAC) feature does that allows for clustering of databases for scale-out performance and high availability. Shetler also says that in Oracle RAC configurations, there will be HA options that allow for data in the columnar store to be replicated across nodes so in the event of a node failure the data is still in memory and available. This replication will make use of RAC.
The interesting thing will be to see if in-memory processing drives a resurgence in NUMA-linked, shared memory systems. "The primary trend is scale-out, but I do not think it is the end of scale up," explained Ellison. "For certain applications, an SMP box is better." Technically, the Sparc M6-32 is a NUMA machine, but we knew what he meant.






