



Convey-Dell FPGA Appliance Accelerates Hyperscale Image Resizing

Convey Computer, a maker of hybrid supercomputers based on a mix of X86 processors and field programmable gate array (FPGA) chips, is teaming up with Dell's Data Center Solutions custom hyperscale server division to bring to market systems that radically accelerate the image processing that is part and parcel of a modern hyperscale application.
Neither Convey nor Dell can name names, of course, about who came to them to create the Accelerated Image Resizer, but it is presumably one of the larger Internet properties and one with tons of static photos that have to be resized for the myriad different devices we have on our desktops, on our laps, in our living rooms, and in our pockets.
Image resizing may not be the typical kind of application that EnterpriseTech is seeking to understand as it pursues use cases for accelerated computing, but consider this. First of all, every web site and every application is getting more visual as the years go by, and for good reason since human beings tend to think visually. (Some are better text processors than others, of course.) Second, the level of acceleration that can be had through the use of FPGAs demonstrates the kind of speedup that other kinds of applications that might also benefit from FPGA acceleration.
Last fall, Convey showed how its "Wolverine" FPGA card could be programmed to radically accelerate the Memcached content caching software that is commonly used in the middle tier of hyperscale Web applications, sitting between the back-end databases that hold Web page components and the Web servers that field requests for pages. Memcached runs in the main memory of server clusters, and can grab the components of a Web page in about 1 millisecond, about an order of magnitude faster than pulling those elements from a relational database. This is not fast enough for many hyperscale datacenter operators and the Memcached appliance that Convey has been selling in partnership with Dell was able to boost the Memcached serving by a factor of about three to five times, while also cutting the latency by a factor of five. At a cost of $25,000 for a server appliance equipped with two dual-FPGA Wolverine cards, which are based on chips from Xilinx, the Memcached appliance offered about three times the bang for the buck compared to a plain vanilla Xeon server.
You can see now why Intel is working on a hybrid Xeon-FPGA chip package, which Data Center Group general manager Diane Bryant revealed last month.
Image resizing may sounds like it is not a big deal, but it is if you have a hyperscale application with lots of static images. Bruce Toal, CEO at Convey, tells EnterpriseTech that a typical page on Facebook has around 100 items that need to be rendered. Traditionally, what companies have done in the past when there was not such a proliferation of device types and screen sizes, is ingest a photo and then render it in perhaps three or four thumbnail different sizes that approximate how it will be used and displayed on devices as Web pages are loaded. "This is never exact, and there is always some sort of resizing that needs to be done on the fly," says Toal. And those thumbnails are not free, either. At one hyperscale account that does it this way, the thumbnails account for 30 percent of its storage. At the other extreme, you can store the image in its original high resolution form and blow out the network linking the device to the datacenter and make HTML5 on the device render each image locally from that high-resolution image. The other option is to put image processing software in a middle layer and have them do real-time rending of images and then pump the sized images for each device over the network on the fly to browsers.
One of the most popular programs for image rendering and resizing on the market is called ImageMagick, and it is this program that Convey has created an FPGA accelerator for, although it can in principle be used for other image rendering applications. ImageMagick is coded in C and uses the OpenMP parallel programming model to parallelize image processing to speed it up on multithreaded and multicore processors. Toal called the program "highly parallelized," and Convey knows how to convert this C and OpenMP to parallelized routines running on the FPGA and can get anywhere from 10X to 100X more parallelism out of this code when it runs on the FPGA. And that is how the FPDA acceleration in the Accelerated Image Resizer is able to accelerate the image resizing of JPEG images by anywhere between 20X and 70X compared to a twelve-core X86 server running the same ImageMagick software. Toal says that the average speedup is on the order of around 48X across a variety of JPEG images.
Robert Hormuth, executive director of enterprise platform architecture and technology within Dell's office of the CTO, says that Dell and its hyperscale customer looked at using highly tuned X86 code as well as GPU coprocessors to accelerate this image resizing workload for the hyperscale customer that initiated this project. The X86 effort did not yield much and Dell's engineers used the on-package GPUs of hybrid X86-GPU chips as well as outboard GPU accelerators to try to goose ImageMagick and did get some pretty good results. While Hormuth did not want to be specific about the different GPUs used, he did say that the effort yielded a speedup of around 7X and 15X. That is about as good as many other applications have done with GPU acceleration, to be honest. The problem is that you need a GPU that burns around 250 watts to get that acceleration.
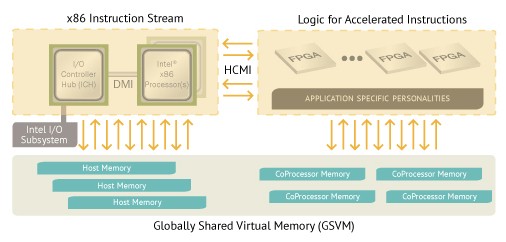
The Accelerated Image Resizer that Dell put together with Convey has two cards based on the Xilinx Virtex-7 XCV690T FPGA, which has support for between 16 GB and 64 GB of its own DDR3 memory and which has up to 32 GB/sec of bandwidth between the FPGA and its memory. Convey's Globally Shared Virtual Memory allows for the FPGA to use the main memory in the X86 server or to keep coherency between the memory in the server and accelerator. Convey uses the memory mapped I/O (MMIO) feature of the PCI-Express bus to maintain this memory coherency, and it makes the programming for the accelerator simpler than it might otherwise be.
This Wolverine FPGA card plugs into a PCI-Express 3.0 x16 slot and has a maximum power dissipation of 150 watts but – and here is the crucial point – it only burns about 60 watts running the portions of the ImageMagick code that are accelerated for the image resizing job. The appliance that Dell has built has two of these cards plugged into a regular PowerEdge R720 server, which is a workhorse 2U, two-socket system based on Intel Xeon E5 processors. Each card yielded somewhere between a 35X and 40X speedup in image resizing, and with two cards you could replace a huge number of servers that are running this work with a fairly modest number of machines – or pull the image resizing work off a content delivery network and stop spending money on that.
The Accelerated Image Resizer card with the ImageMagick acceleration routines went from concept to coded in under two months, says Toal, demonstrating that Convey is getting faster and faster at identifying opportunities and programming the FPGAs. The extremely esoteric nature of FPGA programming using VHDL and Verilog is one of the reasons why FPGAs are not more pervasive in the enterprise, but Convey has come up with tooling that gives it an advantage.
"What Convey has really done is make the economics and the speed of the delivery of FPGAs work," explains Hormuth. "By having this hybrid core approach and programming in higher level languages, you do not have to hire RTL programmers. Anybody can take an FPGA and slap it on a board and start writing RTL. But to get it done in two months like the Convey team did is unheard of. I worked at National Instruments for twelve years and at Intel for eight years, and I spent a lot of time doing ASICs, and it would have taken a sizable team twelve to eighteen months to do what Convey did in two months."
The hyperscale customer that started off this project at Dell and Convey is deploying the ImageMagick accelerators in production now.
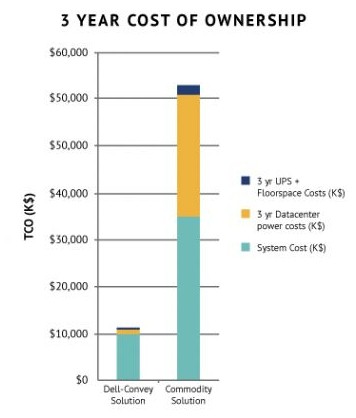
A single Wolverine FPGA card with the ImageMagick acceleration routines on it costs $8,200, but with volume discounts, Toal and Hormuth say that the costs come out as a wash between the FPGA and GPU accelerators, and therefore you can get something on the order of a 35X to 40X speedup for the same cost as a 15X speedup with a heavy-duty outboard GPU accelerator. The real comparison is to what this image resizing costs on plain vanilla X86 servers, and over the course of three years, the Dell-Convey appliance can cut facilities costs by 95 percent, cut power costs by 97 percent, and cut capital costs by 91 percent.
It stands to reason that Pinterest, Shutterfly, Flickr, Facebook, and their peers in the hyperscale datacenter space that have lots of static images are going to want to know more about what Convey and Dell have cooked up. And, not resting on its laurels, Convey is now starting to work with Dell and initial customers on how it might be able to use FPGAs to accelerate streaming media.






