



Oracle Cranks Up The Cores To 32 With Sparc M7 Chip

Say what you will about Oracle co-founder and CEO Larry Ellison, but when the software giant bought Sun Microsystems more than four years ago, for $7.4 billion, he said that he had seen the light and wanted Oracle to control its own hardware and created specialized machinery tuned up to run Oracle's software stack. Despite falling sales in the early years, which have now stabilized and are now growing, Oracle has continued to invest in hardware.
This week at the Hot Chips conference, its chip designers are showing off the forthcoming Sparc M7, the biggest and baddest Sparc processor that either Sun Microsystems or Oracle has ever created. Stephen Phillips, senior director of Sparc architecture, gave the presentation at Hot Chips on the Sparc M7, and John Fowler, executive vice president of systems, spoke to EnterpriseTech about the feeds and speeds at a system level and what it will mean for customers when it ships sometime next year.
With over 10 billion transistors on the die, the Sparc M7 is a whopper and will be, in terms of transistor count, the most dense processor on the market – bar none – when it ships sometime in 2015. The chip will have 32 cores, which is larger than a lot of four-socket servers had only a few years ago and which by any measure would have constituted a supercomputer two decades ago. It will be etched using Taiwan Semiconductor Manufacturing Corp's 16 nanometer FinFET 3D transistor manufacturing node (which is sometimes also called 20 nanometer by some customers) on a 13 metal layer design.
The M7 will be the sixth processor that Oracle has brought to market since the Sun acquisition closed in January 2010, and it is based on the fourth generation of Sparc CMT cores (short for Chip Multi-Threading) designed by Sun and Oracle. The Sparc T3 chip for entry and midrange servers from four years ago was based on the S2 cores, the Sparc T4 and T5 chips for similar sized boxes as well as the high-end Sparc M5 servers had chips based on the S3 cores. The Sparc M6-32 system announced last year and nicknamed the Big Memory Machine was based on the Sparc M6 chip, which also used the S3 cores. Like Intel, Oracle stretches a core design over several processor generations, making a few architectural tweaks between products and changing the performance profile of each chip by changing core counts, clock speeds, cache sizes, or altering other features like system interconnects.
The S4 core has a dual-issue, out-of-order execution unit and it has dynamic threading that ranges from one to eight virtual threads per core. The Sparc chips have had eight threads for a long time, but only in recent years with the S3 cores were the threads able to be dynamically allocated. What this means is that if a workload needs very high single-thread performance, the processor can allocate the chip resources to a single thread on a core, thereby allowing its work to complete more quickly than if it had to share resources across many threads on a core. (Dynamic threading is also available on IBM's Power7, Power7+, and Power8 chips and the latter has eight virtual threads per core just like the S3 and S4 cores from Oracle. Intel's Xeon processor have HyperThreading, which is also dynamic and which provides two virtual threads per core.) The S4 core has two Arithmetic Logic Units, one Load Store Unit, one Floating Point & Graphics Unit, one Branch Unit, and one Stream Processing Unit.
The S4 cores each have 16 KB of L1 instruction cache and 16 KB of L1 data cache. They are organized into clusters of four. The S4 core has a new L2 cache architecture, which allows for the same cycle count for accessing caches but allows for that cache to be 50 percent larger and still get the accesses done in the same compute time. The four cores share a 256 KB L2 instruction cache, which sits at the heart of the four-core cluster, with four independent interfaces to each core that deliver in excess of 128 GB/sec of bandwidth. (Oracle is not saying how much because it would reveal the clock speed of the processor, but Fowler did confirm that the Sparc M7 will spin faster than the current 3.6 GHz of the Sparc T5, M5, and M6 chips.) Each pair of cores shares a 256 KB L2 writeback data cache that also has interfaces to the core that provide more than 128 GB/sec of bandwidth. By having two L2 data caches, the bandwidth into the S4 core is twice as high as was the case with the S3 core. The overall L2 cache bandwidth on the four-core module is more than 1 TB/sec, which makes L2 cache bandwidth more than 8 TB/sec for the entire 32-core processor.
Stepping up the next level in the memory hierarchy is the L3 cache. Each cluster of four S4 cores on the Sparc M7 chip can push data into the L3 cache at 70 GB/sec and pull it out at 140 GB/sec. On the other side of the cache sits the on-chip network (OCN), which has two ports running at 64 GB/sec that move data into and out of L3 cache and onto the OCN to be sent around the interconnect to other caches as S4 cores in the chip request data that is not in their own local L3 cache segment. That L3 cache weighs in at 64 MB across all eight segments, which is 33 percent higher than the cache on the Sparc M5 and M6 chips. The local latency in this L3 cache has been reduced by 25 percent compared to the Sparc M6 processor, says Oracle, and at 1.6 TB/sec of aggregate L3 cache bandwidth across the Sparc M7, that is 2.5X that of the Sparc T5 and 5X that of the Sparc M6. One neat new feature: accelerators on the die and outside of the core can reach in over 256 GB/sec links on the OCN to allocate data into one of the eight L3 cache segments on the die. That OCN has 512 GB/sec of bisection data bandwidth and uses rings to request data, point-to-point links to get responses and a mesh to move data. The four 256 GB/sec ports (two up, two down) also go out to four DDR4 main memory controllers.
With such a beast of a chip, you might be thinking that Oracle would add a L4 cache layer somewhere in the system, and for all we know, it will. What we do know is that the Sparc M7 will have sixteen memory channels across its four DDR4 controllers and will support memory running at 2.1 GHz, 2.4 GHz, and 2.67 GHz. Using 2.1 GHz memory, a single socket will have 160 GB/sec of memory bandwidth, which is 2X that of the Sparc T5 and 3X that of the Sparc M6. Each DDR4 interface has two channels, and the memory links coming off them out to buffer chips on the DDR4 memory cards runs at between 12.8 Gb/sec and 16 Gb/sec, depending on the memory speed. The memory controller allows for DIMM retirement without having to stop the system in the event that a chip fails in the field, and memory lanes can failover with full CRC protection. The memory will top out at 2 TB per socket, twice that of the Sparc M6 system.
The Sparc M7 chip has four PCI-Express 3.0 links that support more than 75 GB/sec of bandwidth, which is twice as much as the Sparc T5 and M6 chips.
For improved power management, the Sparc M7 chip has an on-die power estimator on each core that takes a whack at guessing what the power draw is every 250 nanoseconds, and this feeds data into a power controller that tries to figure out what the power draw is for the entire chip. This is accurate to within a few percent of measured power for the chip, Phillips said in his presentation, and is used to adjust the frequency and voltage of each quadrant of the chip as workloads rise and fall. Each quadrant can be power gated separately.
Both the S4 core and the circuitry wrapped around it have various kinds of accelerators and other functions added to them specifically to enhance the performance of the Solaris Unix operating system, Java middleware and applications, or Oracle's relational databases.
On the Java front, the Sparc M7 has new memory protection features and virtual address masking that will make Java garbage collection easier and more deterministic, according to Fowler. More generically, the Sparc M7 has features to try to get threads that are sharing data to get onto the same S4 core cluster on the die and similarly has features to try to keep LDom logical partitions from thrashing the L3 cache.
The S4 core, for instance, has special instructions to ensure application data integrity, which is done in real-time and which safeguards against invalid or stale memory references and buffer overruns for both Solaris running C and C++ applications and the Oracle database. The Sparc M7 also has database query offload engines and accelerators for in-memory compression and decompression algorithms.
"Decompression can be driven at memory bandwidth rates, so there is no downside to using compression," says Fowler. The on-chip compression leaves the S4 cores leftover capacity to do useful work.
The query accelerator for the Oracle 12c database's in-memory columnar data store does in-memory format conversions, value and range conversions, and set membership lookups. These on-chip database functions were developed in conjunction with the Oracle database team and reside on eight off-core query accelerator engines.

In one example, Phillips showed a query where a SQL command running against an Oracle database was told to find the records in a database of cars where the make was a Toyota and the year of the car was greater than or equal to 2010. The query accelerator fuses both the decompression of the database data and filtering of that data, and the thread where that query is running is stopped precisely long enough by the thread manager in the chip to allow the results to pop up precisely when the thread resumes and needs t5he results of the offloaded query. This is all done in hardware and at memory bandwidth speed, and a Sparc M7 system was able to run that query about 4.7X faster than a Sparc T5 baseline system.
Here is where Oracle thinks the Sparc M7 processor will stack up compared to the processor Sparc M6 over a bunch of different workloads:
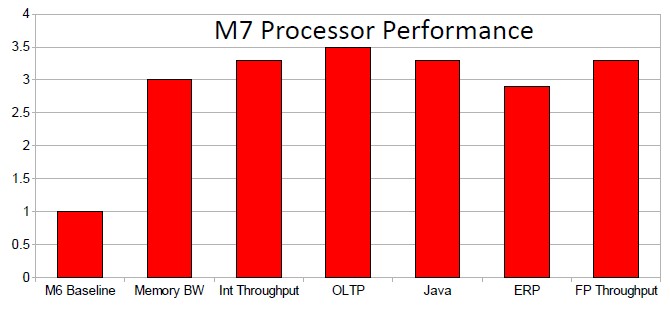
All things being equal, you would expect around a 2.7X bump just moving from 12 cores in the Sparc M6 to 32 cores in the Sparc M7. The microarchitecture and clock speed increase probably make up for most of the rest, since the increased caches and bandwidths are used to keep these cores fed. If half the remaining performance increase comes from architecture, then the Sparc M7 will probably clock in at around 4 GHz, given this performance data above, which averages around a 3.25X bump.
It's All About The System
Way back when, four and a half years ago when Oracle put out its first Sparc roadmap, it said that it would be able to deliver monster Sparc machines in the 2015 timeframe and it showed the steps it was going to take over the years to get there. To its credit, Oracle has by and large stuck to this roadmap, although it has scaled back on the NUMA scalability of its systems even as it did create the "Bixby" interconnect, which during the Sparc M5 and M6 generations could have scaled up to 96 sockets in a single system image with 96 TB of main memory.
In August 2010, Oracle put these stakes in the ground to demonstrate its good faith to those who did not believe Oracle believed in hardware:

This roadmap showed both the Sparc T and M series of processors and their overall throughput and single-threaded performance gains compared to their prior generations of T and M chips. Oracle was promising four times the cores, 32 times the threads, 16 times the memory capacity, and 40 times the database transaction processing from its base T and M machines to the final machine on the roadmap, which had neither a T nor an M on it. The M Series machines were supposed to scale up to 64 sockets, but the commercial version never did reach higher than 32 sockets even though, as we pointed out above, the Bixby interconnect can scale three times as far as what the Sparc M6-32 system can do today.
The late 2014 or early 2015 product, you will notice, never did have a T or an M next to it, just Sparc, and everyone was a little perplexed by this. But, as it turns out, Oracle will be discontinuing the T Series chips, Fowler tells EnterpriseTech, and building future Sparc machines on the M7 processors solely. So it looks like the Sparc T6, which was originally slated around the end of this year into early next year is being cut. The good news is that Oracle delivered the Sparc M6 early and the M7 is right on time and able to handle all kinds of work. It also seems to suggest that Oracle wants a better chip with which to compete against Xeon E5 and E7 processors from Intel and Power processors from IBM, and a low-core count T Series chip was not cutting it. It is also cheaper to make one chip than two – particularly if, like Oracle, a whole line of clustered systems is available using Intel Xeon E5 and E7 processors. Oracle needs to pick its fights, and the Sparc M7 is being aimed at heavy, big memory workloads on scale-up systems.
And as EnterpriseTech has pointed out before, Oracle has made some pretty compelling arguments about why such scale-up systems are better than scale-out clusters. Network latencies between nodes using the first-generation Bixby interconnect for the Sparc M6 are on the order of 150 nanoseconds, 100X lower than for a 10 Gb/sec Ethernet link between nodes in a loosely coupled cluster of Sparc T2 servers with approximately the same performance as the M6-32 system. The M6-32 has 24 TB/sec of bandwidth, about 37X that of the cluster with 16 servers with four 10 Gb/sec ports each. Both setups cost a little more than $1.2 million. For workloads that are bandwidth and latency sensitive, the NUMA machine is better than the cluster.

The Sparc M7 has on-chip NUMA interconnect circuits that will allow eight sockets to be snapped together into a single system image without extra glue chips, just as was the case with the Sparc M5 and M6 chips. An eight-socket machine will have a maximum of 256 cores, 2,048 threads, and 16 TB of main memory, with a bisection bandwidth across the interconnect of more than 1 TB/sec.
Fowler confirmed that the Sparc M7 will use a second-generation Bixby interconnect, and that initially it will scale to 32 sockets. This interconnect will have two links connecting every processor socket to every Bixby interconnect switch; there are a total of twelve switches to link four-socket NUMA nodes together, which is six for one set of links and six for the other. The bi-section bandwidth on this switch interconnect is 5.2 TB/sec, which is four times that of the first-generation Bixby interconnect used in the M6-32 system. This M7-32 machine, as we presume it will be called, will have 1,024 cores, 8,192 threads, and up to 64 TB of main memory.
Interestingly, the updated Bixby NUMA interconnect will allow for cache coherent links between the Sparc four-socket nodes and will also allow for non-coherent links. This will allow a big Sparc M7 machine to function as a cluster for Oracle RAC database clustering software, using the Bixby interconnect instead of 40 Gb/sec InfiniBand as the Exadata database clusters do. The Bixby interconnect and SMP glue chips also have low-level message passing protocols etched on them specifically to pass messages used in database clusters.
When asked about what the performance advantage would be comparing an InfiniBand or Ethernet cluster running Oracle RAC and the Sparc M7-Bixby setup using the non-coherent memory clusters, Fowler said that the difference "would not be subtle."
The Sparc M7 chips are in the late stages of testing now and will come out in systems in 2015. Solaris 11 will be supported on the machines, with Solaris 10 being supported inside of LDoms and Solaris 8, 9, and 10 being supported inside of Solaris containers for customers who have vintage workloads.






