



Mangrove: Fujitsu’s Experimental Green Data Center Design
Creating a green data center is not just a matter of locating the facility in Norway to keep the servers cool or plugging into a string of hydroelectric dams. The next generation green data center will be re-conceptualized from the concrete floor to the virtual network.
In this move away from traditional data center designs from the ground up, the servers and networks will be redesigned and the physical infrastructure of the building will be designed around the servers. It will be efficient and flexible, easy to upgrade and to reconfigure. It will dynamically pool resources from different components. It will use virtualization and new technologies to improve performance and reliability, to lower costs and to save energy.
That, at least, is the vision of researchers at Fujitsu Laboratories who are trying to create a new, integrated system architecture for future green data centers. The project, called Mangrove, is described in a paper as an attempt to achieve “total optimization by vertically integrating servers, storage drives, networks, middleware, and facilities.”
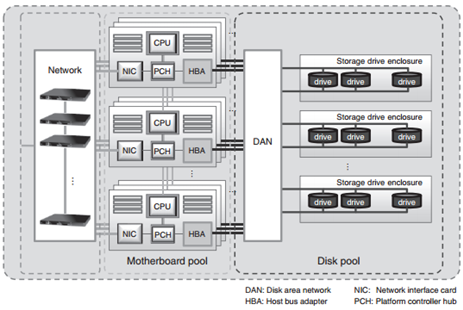
The design starts with a fundamental idea: tear apart the servers into components and reconnect them through software and networks. Specifically, Fujitsu Laboratories plans to separate the server into three components: the CPU motherboard, the storage device, and middleware to control them. Instead of installing racks of complete servers, Mangrove calls for the installation of groups of motherboards – “motherboard pools” – and groups of memory devices, or “disk pools.” With the proper interconnections and software, Fujitsu researchers believe they can network together hardware configurations to meet any specification, and alter the configurations when needs change.
Disk Pool Configuration
This approach has the potential to cut costs and energy requirements in several ways. First is the layout of the facility and cooling of the components. Rather than building racks for bulky servers, data center managers would be able to use more compact racks designed specifically for either motherboards or for disks. In that way, many more components can be squeezed together to save space. Cooling the components should be easier, since high heat-generating CPU pools can be separated from the pools of HDDs or solid state disk drives, which don't generate as much heat. Each can be relegated to areas of the building cooled to the proper temperature.
But the real advances are supposed to come from the software and networks that link components from the CPU pool to those from the disk pool. The software suite, including networks, operating systems and middleware, is designed to dynamically configure servers out of banks of CPUs and banks of memory devices. Once configured to meet the needs of a particular application, each setup should not need to be changed very often. But if a CPU board or memory device should fail, the software is designed to replace them with other devices in the pool.
These software suites are custom-designed by Fujitsu. Aside from a regular Ethernet network in the data center, there's a special network for connecting the disks to the CPUs. It's called DAN, for Disk Area Network, to distinguish it from a SAN (Storage Area Network.) With DAN, one disk drive does not have to be shared by multiple nodes, but should be able to be configured with CPUs in any combination to meet a particular need. For example, connect one motherboard to four disk drives to create a general-purpose server, or add many more disk drives to turn the configuration into a storage server, according to the paper.
The brainpower behind all this is a software program called MangroveManager. That's the program that will choose and connect together the proper number of disks and CPUs into a configuration that will meet the needs specified by the user. It also makes the components work together as a single system by installing the operating system and middleware on the constructed server.
Interested in a RAID for example? Fujitsu says its software can automatically put together a Redundant Array of Independent Disks for you, and even re-configure it later, without you ever connecting or disconnecting a cable. Here's the process:MangroveManager chooses motherboards and memory devices from the pools and tells DAN to make the connections. MangroveManager installs the OS, as well as a piece of middleware created to build RAIDs. And here's where the names and acronyms get complicated. The middleware program is called Akashoubin (the Japanese name for a large reddish-brown Asian kingfisher.) This bird is divided into two parts: Akashoubin Manager (AsbM) and Akashoubin RAID Controller (AsbRC). AsbM controls AsbRC, which in turn controls the disks and their RAID functions. In addition, if any of the CPUs or storage devices in a configuration fails, Akashoubin can replace them with other units from the pools without moving any physical parts.
Sure, it may seem simple enough, but the researchers admit that the whole system is still a work in progress. Several components are still under development, including several pieces of the data center network. This network is a conventional Layer 2 LAN/SAN, but it needs to meet the criterion of the Green IDC by providing “optimization of cost performance by vertical integration,” says the paper. In order to achieve that, Fujitsu wants the system to be able to scale to something on the order of 2,000 servers, to provide flat characteristics (uniform delay and throughput across all servers,) to offer security and reliability, and to sport low-cost power-saving features.
To reach those goals, the Fujitsu Research team is still working on several components. One is a “high-density, large-capacity switch” that should, for example, be able to relegate heavy control plane processing to the CPU pool but assign light management processing tasks to the switch's own local CPU. That way, the amount of processing required is proportional to the cost of the processor used for the task. The same efficiency strategy goes for a network manager that will be able to manage the virtualization and, say, put switches with a light load to sleep until needed. They're also trying to build high-speed optical interconnects out of inexpensive consumer-level optical technology.
And in order to use the capabilities of this reconfigurable data center to create a more perfect data center, they're evaluating a new VM placement design system. It is supposed to not only create new designs automatically in response to new specifications from a system manager, but will include a “scoring system” that will help optimize placements by rating their effectiveness according to a combination of several criteria. Several criteria would make up the score, such as reducing power consumption, minimizing software-license fees, enhancing fault-tolerance and reducing costs. Users can also change the relative importance of each of these criteria (such as giving more weight to reducing power consumption) so that the final score of any placement will be customized to meet their specific needs.
So there's still much work to be done. Fujitsu Laboratories says the next step is a “proof of concept” study, in which everything described in the paper is integrated into a prototype system. If that prototype shows promise, the concept will take a big step toward reality. Once they can prove the whole thing works, then you can build it next to hydroelectric dams in Norway and you've got an ideal green data center.
The full paper is published in the Fujitsu Scientific & Technical Journal here.






