



Invisible OpenCL and APU Chips Drive Acceleration

AMD has some stiff competition in the server space. The company thinks that the combination of CPUs and GPUs together, what it calls Accelerated Processing Units (APU), has a place in the datacenter. And it is fostering the software development tools that make it easier to dispatch programs to the GPUs on its chips to make them run faster than they would on CPUs alone.
This will be the major theme on the server front at the APU Developer Conference that AMD is hosting in San Jose this week. The company is also showing off some early benchmark test results to show how well its APUs can accelerate Java applications.
AMD has just notched up a win with Hewlett-Packard, which will be making server cartridges for its Moonshot 1500 hyperscale servers using the company's "Kyoto" Opteron X server chip. AMD believes it can win server footprints in hyperscale machines like the Moonshot based on the combination of CPU and GPU performance that its current Kyoto and future "Berlin" Opteron X chips will deliver. It all starts with the chip, and then works its way up through the software stack to the tools that will allow applications to more transparently offload work from the CPU to the GPU within the APU, Margaret Lewis, director of server software planning at the company, tells EnterpriseTech.
Here are the basic feeds and speeds of the Kyoto Opteron X:

The Kyoto chip has four of AMD's 64-bit "Jaguar" cores on a die, each with 32 KB of L1 instruction and 32 KB of L1 data cache on the core. The four cores share 2 MB of L2 cache memory. The chip has an on-die DDR3 memory controller and it can address up to 32 GB of main memory running at 1.6 GHz. (To add more memory than this would require boosting the memory lanes and therefore increasing the size and footprint, in terms of real estate and power usage, of the memory controller, which is why AMD did not do this.) The chip has an eight-lane PCI-Express 2.0 controller, a two-port SATA disk controller, and a two-port USB controller as well. It comes in a package called FT3 that gets soldered onto the motherboard directly rather than plugging into a socket.
The Opteron X1150 has the GPU coprocessor turned off and runs at 2 GHz, while the Opteron X2150 has the GPU turned on and runs at 1.9 GHz. The GPU has 128 of the same cores that are used in the Radeon 8000 HD graphics chip. It is rated at a mere 9.3 gigaflops at doing floating point math at double precision but can handle 154 gigaflops at single precision. For a lot of workloads – seismic processing, DNA analysis, video transcoding, facial recognition are just four – single precision math is what matters, so the Opteron X APUs will find uses. Particularly given the incremental cost of the GPU. The X1150 costs $64 when you buy them in 1,000-unit trays from AMD, and the X2150 costs $99. So that 128-core GPU coprocessor costs only $35. While 154 gigaflops is not much single-precision oomph, $35 is not much, either. In fact, it is about a quarter of the cost per gigaflops of an Nvidia K10 GPU coprocessor designed explicitly for single-precision workloads. A full rack of Moonshot servers with ten enclosures, each with 45 nodes per enclosure, would deliver around 277 teraflops of single-precision floating point performance.
AMD has not said much about next year's Berlin APUs, but we can assume that both the CPUs and the GPUs will have more oomph. Here is what AMD has said about the Berlin chip publicly this far:
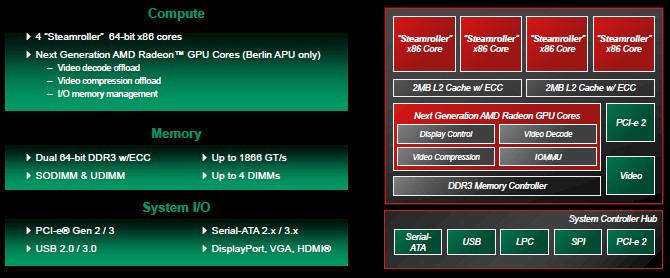
The Berlin Opteron X chip will have four of the "Steamroller" server cores, which will be considerably heftier than the Jaguar cores that were designed originally for laptops. Each pair of cores will have their own L2 cache memory, and the chip will offer unified memory access across the CPU and GPU using AMD's Heterogeneous System Architecture (HSA) approach. AMD is not providing precise feeds and speeds, but says that the Berlin chip will have twice the compute performance and twice the memory capacity as the Kyoto Opteron X chip, and will offer 7.X times the gigaflops per watt as an Opteron 6386SE chip. The Berlin chip will be available in the first half of 2014, and will sport enough next-generation Radeon cores to "eliminate the need for discrete graphics for GPU processing," as AMD puts it.
With all of this CPU and GPU compute capability on a single package and the unified memory addressing, is targeting larger compute jobs with Berlin than it was with Kyoto:

Specifically, Lewis says that the APUs will be suitable for Monte Carlo and other simulations at financial services firms and seismic analysis at oil and gas companies – again, both of which need single-precision math more than double precision. Online gaming companies and media companies that do a lot of video transcoding on the fly are going to take a hard look at the Kyoto and Berlin chips, too, says Lewis, and so will those setting up Hadoop clusters and NoSQL data stores like Cassandra and MongoDB. Machine learning algorithms using Mahout on Hadoop or Graphs are expected to see a boost from APUs, too.
To get these workloads running in a hybrid CPU-GPU mode is not an easy thing, and AMD knows it. But it has been working with compiler and library makers to make it easier.
"The problem has been – and this is a world that Kyoto lives in – is that OpenCL is a fine tool, but for cluster developers, they are used to writing code for CPUs and OpenCL is a bit of a foreign language for them," explains Lewis. "They have to create OpenCL kernels and then figure out how to put those kernels into their traditional programs. What we have been doing as we have been approaching Berlin is to look at what we can do to make the tools easier by infusing the GPU directly into the tools. What we are trying to do is put OpenCL on the backend of the compilers and libraries that developers already use. We want to meet the developer where they are writing code. So if developers write in Java, they need Java APIs they can use and the OpenCL needs to be under the covers."
Here is the stack of server development tools that are being tweaked to link to the GPUs through OpenCL more transparently:

Lewis says that the clMath libraries were just updated in August so you can push them to the GPU for processing where appropriate. And PGI has a beta of its C, C++, and Fortran compilers offloading to the GPUs in an APU in beta testing now. The PGI tools are expected to be generally available in the first quarter of next year.
For enterprise customers, support for accelerating Java on GPUs is key – something that IBM's Java CTO, John Duimovich, was pressing for in September at the JavaOne conference. Duimovich showed a benchmark test result on a sorting algorithm that had a 48X reduction in latency dispatching parts of the sort to an Nvidia GPU rather than running it on the CPU. This particular test was done using the Project Aparapi tool, which allows parallel chunks for Java bytecodes to be converted to OpenCL and run on the GPU coprocessors. Java acceleration will be more complete when Project Sumatra Stream APIs being co-developed by AMD and Oracle are added with the Java 9 virtual machine. The combination of Aparapi, Sumatra, and HSA, says Lewis, will allow for Java acceleration without any code changes. This chart shows the evolution of GPU-accelerated Java:

AMD has run some initial benchmark tests of its own to show how GPUs can accelerate Java, and is sharing the results for the first time. The benchmarks were run on a four-core APU processor with Java 7 running an N-body simulation in a very single-threaded mode on the chip, shown in the red line below:
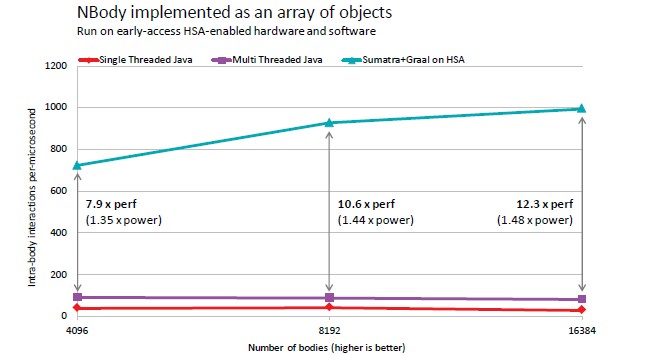
The N-body problem simulates the interaction between a number of bodies, as the name suggests, and is very compute intensive. The more processing capacity you have, the larger the number of interactions between the bodies you can simulate; more compute should also allow for more bodies to be simulated as well. The blue line added in multithreaded Lambda expressions to the Java code, which will be part of Java 8 next year. This change allowed for the N-body application to run in multithreaded mode with around a factor of 2X increase in the number of bodies simulated. With the addition of the Sumatra implementation expected in 2015 or 2016, depending on who you ask, and the shared virtual memory for the CPU and GPU enabled by AMD"s HSA, this same simulation offered anywhere from a factor of 7.9 to 12.3 performance speedup (as reckoned by the number of interactions simulated) with anywhere from a factor of 1.35 to 1.48 increase in power.
Those are tradeoffs that Java shops will be happy to make.






