



IBM Power8 Rollout To Start With Scale Out Clusters

Officially, IBM has said that would be launching its twelve-core Power8 processors in new Power Systems servers and PureSystems converged systems sometime around the middle of the year. But as EnterpriseTech has previously reported, the word on the street is that IBM is getting ready to get the first Power8 machines into the field sometime around the end of April or early May. If the latest scuttlebutt is right, then it looks like the first Power8 systems will be entry machines that can be clustered up to run supercomputing simulations, Hadoop analytics, parallel databases, and similar modern distributed workloads.
Or, as the case may turn out, homemade Power8 systems that might possibly be used by Google in its vast infrastructure or souped up boxes aimed at high frequency traders, as EnterpriseTech has previously told you about.
A late April or early May launch would coincide with the Impact2014 event that Big Blue is hosting for customers and partners in Las Vegas from April 27 through May 1. The company is also participating in the annual COMMON conference for customers of its IBM i (formerly OS/400) midrange system, which runs from May 4 through 7. While the IBM i server business is considerably smaller than it was 15 years ago at its peak, Power Systems machines running IBM i are still used by around 150,000 customers worldwide and that operating system is only available on Power-based servers from IBM. Significantly, most of those customers tend to buy entry-level machines because their workloads are fairly modest by modern standards, and this is also the same class of machine you might use if you wanted to build a Hadoop cluster running atop Linux on Power chips. Doing one big push to cover many different markets make sense, particularly with IBM trimming costs as Power Systems revenues have been on the decline.
Just like other chip makers – notably Intel, AMD, Oracle, and Fujitsu in the enterprise space – IBM staggers its chip launches, although in this case it controls both the chips and the systems unlike Intel and, for the most part, AMD. For the past several processor generations, IBM has started the Power chip launch in the middle of its line, with machines that have from 4 to 16 sockets in a single system image. These are relatively low volume products, so it gave IBM time to ramp up its 45 nanometer process for eight-core Power7 chips and 32 nanometer process for eight-core Power7+ chips. The Power7+ had some microarchitecture improvements to boost per-core performance and a whole lot more cache per core to push the performance up even further. Then IBM launched entry machines using the chip, and in the case of the Power7, finished up with a 32-socket box that has a specially packaged version of the Power7 that allows it to clock higher than in the entry and midrange machines. The high-end machine in the Power Systems line does not get an upgrade to the "plus" variants of any processor, by the way. Whether or not IBM maintains this practice remains to be seen.
If history is any guide, IBM will have a high-end Power machine with 16 or 32 sockets available by the fall, for the big year-end sales push.
Starting at the bottom of the line this time around makes sense given that Intel refreshed its Xeon E5 processor lineup back in September with variants with six, ten, and twelve cores. If IBM wants to sell scale-out clusters based on Power8 chips against Intel, systems based on Xeon E5 v2 processors are the ones Big Blue has to beat.
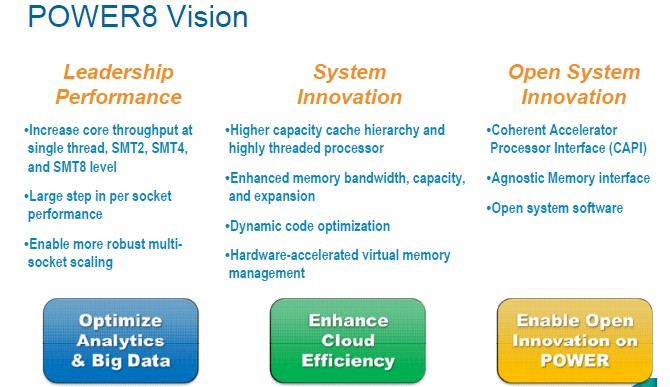
The mantra coming out of IBM's Systems and Technology Group about the Power8 launch is cloud, big data, open, and scale out. The open part means linking the Power8 launch to the OpenPower Consortium, which IBM started last year with Google, Nvidia, Tyan, and Mellanox Technologies. The consortium now has 14 paid members who are contributing to firmware, hypervisor, motherboard, and other parts of the Power8 system design, and one company, a startup called Suzhou PowerCore, licensing the Power8 chip to create its own variants of the processor for the Chinese server, storage, and switching markets. Sources at IBM tell EnterpriseTech that there are more than 100 other companies that have expressed interest in joining the OpenPower Consortium.
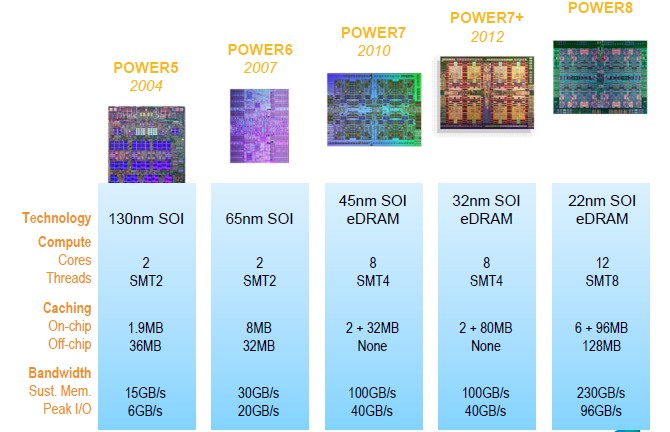
The Power8 chip, like its predecessors, is probably relatively large compared to a Xeon E5 part and will probably consume more electricity and dissipate more heat, even though it uses a 22 nanometer process that puts it on par with what Intel can deliver at the moment. IBM's 64-bit Power chips have always been larger and hotter than their Intel equivalents, but they make up for it with more throughput, enabled by radically higher I/O and memory bandwidth. The twelve-core Power8 chip will sport 96 MB of L3 cache on the die and will have an additional 16 MB of L4 cache on each "Centaur" buffer chip embedded on the memory cards used with Power8 systems. (On a 16-core system linked gluelessly by the NUMA interconnect on each Power8 chip, that is a total of 2 GB of L4 cache on a system that can have 16 TB of main memory across those sockets. That machine will have 192 cores, and the interconnect has an extra link in it now so any socket can get to any other socket in one or two hops instead of a maximum of three.)
The interesting thing to consider as we head out to the GPU Technical Conference hosted by Nvidia is precisely how Big Blue and the graphics chip maker are going to collaborate on ceepie-geepie systems starting with the Power8 generation and moving forward from there. Back in November at the SC13 supercomputing conference, Brad McCredie, vice president of Power Systems development within IBM’s Systems and Technology Group, told EnterpriseTech that the two companies were in the process of modifying the Power8 systems to better accommodate Nvidia's Tesla GPUs and would be tweaking the IBM software stack to accelerate it with those GPUs. The Power8 chips have on-die PCI-Express 3.0 peripheral controllers. The jump to PCI-Express 3.0 is necessary to quickly move data back and forth between the CPU and GPU as they share work; the PCI-Express 2.0 used on Power7 and Power7+ chips was too slow to push these accelerators or high-speed InfiniBand and Ethernet cards.
To simplify the programming model for hybrid systems and speed up the data transfers between the CPUs and GPUs, IBM created what it calls the Coherent Accelerator Processor Interface, or CAPI, which will be first implemented on the Power8 chip. This is an overlay for the PCI protocol that creates a virtual memory space comprised of the CPU main memory and any memory used by any kind of accelerator that plugs into the PCI bus – GPU, FPGA, DSP, whatever have you.
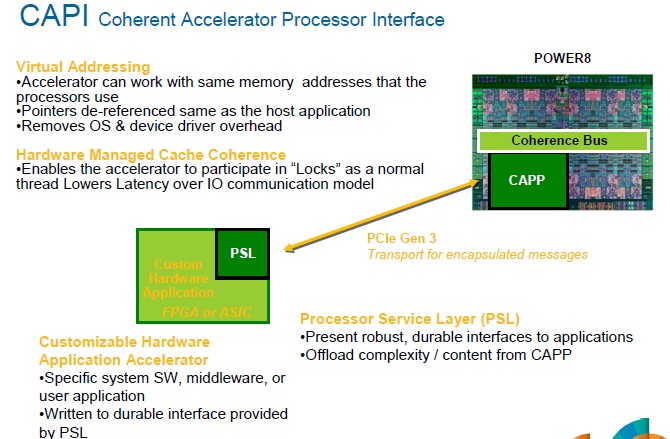
The CAPI interface will work with the Tesla GPU accelerators and the virtual memory in the CUDA environment to manage the movement of data between main and frame buffer memory, transparent to the application. Nvidia announced unified memory between the X86 CPUs and Tesla GPUs with CUDA 6 last fall ahead of the SC13 event. (It is probably not a coincidence that the accelerator side of the chart above is in two shades of green and black. The nearly unreadable print in the light green box says "Custom Hardware Application, FPGA or ASIC" in case you can't read it.)
IBM has been very clear that it wants to accelerate Java workloads with GPUs, and work is progressing to get such acceleration into the field perhaps by 2015 or so. That is also, perhaps not coincidentally, when IBM expects to have a clean-slate system design based on Power chips and future Nvidia GPU coprocessors in the field that more tightly links the two together. Java, of course, is the language of choice for a lot of enterprise applications, mainly because it is easier to work with than C or C++ and more widely known than any of the legacy programming languages on IBM systems.
The thing to remember, as we have pointed out before, is that IBM can have a much tighter partnership with Nvidia than either Intel or AMD can. It is reasonable to expect for the two companies to work more closely together on traditional supercomputing systems as well as other kinds of clustered and accelerated systems used throughout enterprises. Hopefully, the two companies will make some of their long-term plans clear at the GPU Technology Conference.






