



Future Nvidia ‘Pascal’ GPUs Pack 3D Memory, Homegrown Interconnect

Graphics chip and GPU accelerator maker Nvidia is hosting its GPU Technical Conference in its stomping grounds of San Jose, California this week, and company co-founder and CEO Jen-Hsun Huang tore up the GPU roadmap, replacing the future “Volta” GPU expected around 2016 or so with a much better device that is code-named “Pascal.” The Pascal GPU will sport 3D stacked memory, just like Volta was expected to, but also adds a high-speed interconnect for linking CPUs and GPUs called NVLink that was under development and that the company says can be pulled into its GPUs earlier.
While this new interconnect was pulled in, the hardware-assisted unified memory that was expected with the “Maxwell” family of GPUs has been pushed out, and Ian Buck, general manager of GPU computing software at Nvidia, confirmed to EnterpriseTech after the opening keynote by Huang was over. The CUDA 6 development tools announced at the SC13 supercomputing conference last year already support a software-based version of unified memory, but Maxwell was expected to implement this in transistors to speed up performance. It is not clear why Nvidia made this change. It could simply be more difficult to do than Nvidia anticipated or it could have something to do with the fact that Nvidia is teaming closely with IBM on aligning its future Power processors with Tesla GPU coprocessors for accelerating traditional supercomputer workloads (technical simulation and modeling) and an increasing portfolio of enterprise applications that have parallel elements.

The changes with regard to hardware-assisted unified memory with the Maxwell GPUs may also be why Nvidia did not talk about the design of the Maxwell chips at the GPU Tech Conference even though it has started to ship the first GPU for client devices that is based on Maxwell.
The important thing for customers looking to accelerate workloads is that Nvidia is expanding out beyond the X86 market and figuring out how to interface with IBM’s Power chips, and that it is getting the 3D stacked memory for the GPU out the door on time (albeit with the Pascal instead of the Volta device) and the NVLink interconnect is coming to market early. The Pascal GPU is going to address a lot of problems that affect accelerated computing with GPUs.
The issues are ones that Takayuki Aoki of the Tokyo Institute of Technology did early research on with the Tsubame ceepie-geepie supercomputer, explained Huang. Using GPUs and CPUs together has a number of different bandwidth bottlenecks. The bandwidth between the CPU and its DDR3 memory is on the order of 60 GB/sec in a modern X86 processor, and on a top-end Tesla GPU coprocessor, the bandwidth between the GPU and its GDDR5 frame buffer memory is a lot faster at 288 GB/sec. But the PCI-Express 3.0 bus linking the CPU to the GPU is only delivering 16 GB/sec of bandwidth.
The study by Aoki showed that the performance per unit of data (flops per byte) actually levels off asymptotically as the amount of data grows because of these bottlenecks, and because of inter-GPU bandwidth issues over the PCI-Express bus flattens out because of communication overhead as you add GPUs to the system.
“We have to take these bottlenecks head on,” said Huang.

Nvidia CEO Jen-Hsun Huang holding a mockup of the future "Pascal" GPU card
The key new technology that Nvidia Research came up with is NVLink, which is a point-to-point interconnect that is a superset of the PCI-Express protocol. It was developed under the guidance of Bill Dally, who is chief scientist at Nvidia and who quite literally wrote the book on supercomputing interconnects. (Principles and Practices of Interconnection Networks, to be precise.) Huang said that NVLink uses differential signaling with an embedded clock, and the programming model is basically PCI-Express with enhanced direct memory access (DMA) capability across that peripheral interconnect.
“Software can adopt this interface very, very easily,” said Huang. “It enables unified memory between the GPU and the CPU and, in the second generation, between the GPU and the CPU cache.”
PLX Technologies and A3Cube are similarly taking aim at Ethernet and InfiniBand riding on the PCI bus as they promote PCI-Express switching as a lower-latency and higher bandwidth interconnect for clusters.
Huang said that NVLink would bundle up eight bi-directional PCI-Express lanes into a brick, and then in the first generation have four of these bricks enabled as fat pipes between the computing elements; with the second generation, this would be expanded to eight bricks. This, Huang said, would increase the bandwidth between these devices by between 5X and 12X. It can be used to link GPUs to other GPUs as well as CPUs to GPUs. Discrete GPUs have always had PCI-Express controllers on them, which is how they are able to talk to the PCI and PCI-Express buses.
The NVLink interconnect requires changes to be made to both the CPU and the GPU that are using them, and IBM has come forward and said that it will be licensing the technology from Nvidia to include it on an unnamed future Power processor.
IBM, you will recall, has its own variant of a souped up PCI-Express protocol to create a virtual memory space between Power processors and any accelerators (GPUs, FPGAs, DSPs, whatever) that are linked to them. This is called the Coherent Accelerator Processor Interface, and it is set to debut with the Power8 chip, if the rumors are correct, in late April. It looks like both companies were developing their own approaches to this problem, and it is not immediately clear how they will be reconciled. Thus far, neither IBM nor Nvidia are talking about specifics, but they are partners in the OpenPower Consortium and Nvidia wants IBM to sell more power machinery and thus weaken Intel as much as IBM wants to have some sort of differentiation that X86 processors do not to help it do so. They are going to work this out, technically and economically. They have to, particularly with an IBM Power8 chip delivering 230 GB/sec of sustained memory bandwidth and 96 GB/sec of sustained I/O bandwidth. To a certain way of looking at this, Big Blue would have to invent something like NVLink if Nvidia had not because the bandwidth bottlenecks will be worse between the Power8 CPU and the PCI-Express 3.0 bus as it is.
The NVLink is based on a differential, bi-directional, dual simplex PCI-Express 3.0 link running at 20 Gb/sec, and a brick, as Nvidia calls it, bundles eight of these links together for a total of 20 GB/sec of bandwidth. The Pascal GPUs will have between four and eight bricks per package for linking out to other GPUs and to NVLink-enabled CPUs. A technical note put out by Nvidia says NVLink will deliver between 80 GB/sec and 200 GB/sec of bandwidth. Here are the various scenarios where NVLink can be used:
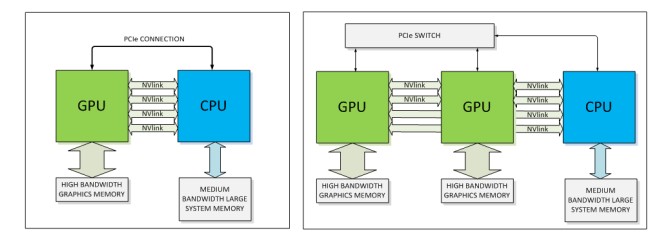
In the chart above, the diagram in the left shows four NVLink pipes lashing the CPU to the GPU plus a regular old PCI-Express link that is used for signal management between the systems. If you have more than one GPU coprocessor in the system, you need a PCI-Express switch to manage the signals but all of the traffic goes over the NVLinks. The links shown have the CPU linked to the GPU on the top, the GPU linked to the CPU on top as well, and the CPU passing through the first GPU to the second natively as well. It is not clear what the latency differences are as signals go through GPUs to get to each other and to the CPU.
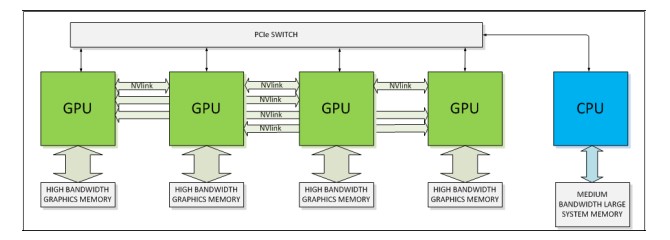
In a system that does not have support for NVLink built into the processors – for instance, very likely all Xeon and Opteron processors from Intel and AMD unless the two companies license NVLink from Nvidia or create a clone – you can use NVLink to hook the GPUs together into a kind of GPU cluster and link out to the CPU over the PCI-Express switch from each of the GPUs. Obviously, this scenario would work best where most of the data is resident on the GPUs. In fact, it may work best if you think of the CPU as some kind of master head node that doesn’t do much in the way of computation at all.
The interesting thing to contemplate is using NVLink as a broader fabric to stitch together lots of server nodes packed with CPUs and GPUs.
Memory bandwidth to get a boost
While the GPU has plenty of bandwidth into its own GDDR5 memory, Huang says “we would surely like to have more” because that will be necessary as the number of CUDA cores on each successive generation of GPUs goes up. “The challenge is that the GPU already has a lot of pins,” explained Huang. “It is already the largest chip in the world and the interface is already extremely wide. So how do we solve that problem? We can go wider, which makes the package enormous, we can make the signaling go faster, but that translates into too much energy consumption. And we know that we are power limited in almost every application we are pursuing.”
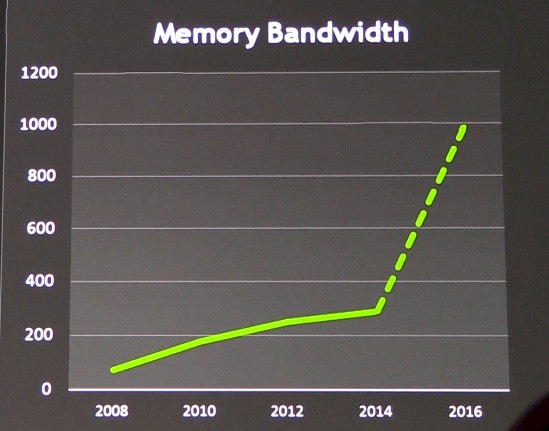
The answer to the memory bandwidth problem is 3D stacked memory, which will be incorporated onto the Pascal GPU as it was planned to be for the Volta GPU. Nvidia will be adopting the High Bandwidth Memory (HBM) variant of stacked DRAM that was developed by AMD and Hynix, not the Hybrid Memory Cube (HCM) variant developed by Micron Technology and Intel. The memory interface on the Pascal GPU will be on the order of “thousands of bits,” according to Huang, compared with hundreds of bits with the current “Kepler” family of GPUs.
Over time, Nvidia will boost the memory bandwidth for the local memory on a discrete GPU using 3D stacked memory by a factor of 2X to 4X, according to Huang. That could mean that Pascal gets a factor of 2X improvement of on the memory bandwidth and a follow-on GPU gets the 4X pushing bandwidth up to 1 TB/sec, but the chart above that Huang flashed up showed 1 TB/sec of memory bandwidth on the GPU by 2016, and that is when Pascal is expected. Go figure. It is likely that there will be different memory capacities and bandwidths for the Pascal GPUs that ship in 2016.

The important thing is that the 3D stacked memory that goes onto the GPU package will have more than twice the capacity of, we presume, Maxwell GPUs and four times better energy efficiency because 3D memory is not only stacked close to each other and linked with through silicon vias (TSVs) but is also close the GPU, which makes it four times more energy efficient and also allowing for voltage regulators to be placed right next to the GPU-memory complex. All of these energy savings will allow or Pascal to stay in the same 225 watt to 300 watt thermal band of current Nvidia discrete GPUs, and the savings in energy consumed by memory will be used to give the GPU chips more performance.
That entire Pascal package is about the size of a smart phone and is one-third the size of a current PCI-Express discrete GPU card.
In the image above, the GPU is at the center with four 3D stacked HBM memory modules nearby on a single substrate of some kind. (Nvidia is not revealing what it is.) The NVLink is underneath the GPU and is designed to snap the GPU card onto a system motherboard like a mezzanine card for Ethernet or InfiniBand adapters or even RAID 5 disk controllers do today. In effect, it is a socket of sorts for the Nvidia GPUs, and it is in fact akin to the way the Tesla GPUs are packaged up for the blades in the “Titan” supercomputer at Oak Ridge National Laboratories, a ceepie-geepie built by Cray.
Sumit Gupta, general manager of Tesla GPU Accelerated Computing Business unit, says that Nvidia is happy to license the NVLink technology to any system or CPU makers, and adds that it is not a big deal for them to cope with a different socket or slot for a peripheral device. At the high-end of the supercomputing market as well as among the hyperscale datacenter operators, custom or semi-custom iron is already the norm.






