



Telco Calls On GPU-Native SQream SQL Database
Using GPUs to accelerate processing started in earnest six years ago with floating point number crunching in the supercomputing space, but now it is moving into database processing and analytics. There were a slew of announcements from various vendors relating to analytics workloads at the GPU Technology Conference hosted by Nvidia this week in San Jose, and one of the more interesting ones came from a startup called SQream Technologies, which is working with French telecom provider Orange to commercialize a SQL database that runs atop Tesla GPU coprocessors and can boost transaction speeds by a factor of 100X compared to the speed of a parallel X86 cluster running a distributed relational database.
SQream is located in Israel and was founded four years ago by Ami Gal, the company's CEO, and Kostya Varakin, its CTO. Gal was formerly vice president of business development for Magic Software Enterprises, an application development tool provider for IBM mainframe and midrange platforms, while Varakin spent the several years as a parallel programmer at Intel developing code for chip design, including database code. The idea behind the company's Analytics Engine database management system is a simple one: replace a rack-scale data warehouse system with a server appliance stuffed with GPUs to run complex SQL queries a lot faster and for a lot less money.
In a presentation at GTC, Ori Netzer, vice president of product management at SQream, said that dealing with datasets above 10 TB in size was an issue for most enterprises. If you go with a parallel data warehouse, then you spend a lot of money to get scalability and reasonable performance. And if you try to save some money and go with Hadoop and MapReduce with an SQL layer, you end up needing a bunch of technical experts to implement it and it is still not quite compliant with the ANSI SQL standards.
So the first design goal for the Analytics Engine database was to do queries with plain, old-fashioned SQL, and not require companies to learn a variant of SQL or go so far as to implement Hadoop with MapReduce and Hive or one of the new SQL layers such as HAWQ from Pivotal or Impala from Cloudera. The second design goal was to get a server equipped with Tesla GPU coprocessors that might cost something on the order of $15,000 to $20,000 to do the work of a parallel X86 cluster that might cost somewhere around $7 million. The target dataset to demonstrate the performance was a 3 TB database with 18 billion records, and the goal was to provide the same query runtimes against that database on the appliance equipped with the Analytics Engine as was done with the parallel database. The main competitors in the parallel data warehouse business are, of course, Teradata with its Enterprise Data Warehouse, IBM with its Netezza.
Those are pretty tall orders, and it is not just a simple thing to make a relational database run on a GPU. Netzer tells EnterpriseTech that the Analytics Engine database was custom coded by SQream and is not based on any existing open source technology, and it took years to develop because of a number of challenges.
"The downside of all of this is the PCI-Express bus, which as we all know is an additional bottleneck on top of the I/O," Netzer explained. "And even with the wonderful Tesla K40 with 12 GB of memory, that is still pretty limited you have to admit. There are also new algorithms, new methods required to write to the GPU. This is not something that is straightforward to program."
An X86 server with two Tesla K40 GPU accelerators running Analytics Engine can cope with 100 TB of raw data. At the moment, Netzer says, the company can only scale up the performance of its database within a single server node. A high-end server can usually have as many as eight Tesla GPU cards plugged into it, provided it has enough power and cooling, of course, so that gets you to a raw database size of around 400 TB. The SQream database cannot scale across multiple nodes as yet, and Netzer is making no promises that the system will allow for clustering in the future. But when asked about the possibilities of marrying Nvidia's future NVLink interconnect for GPUs, which comes out with its future "Pascal" graphics chips due in 2016, with PCI-Express switching, Netzer said this was a very interesting possibility to scale out the performance of Analytics Engine. Very fast InfiniBand or Ethernet links with direct memory access could also be used to cluster such machines, and using a GPU-aware technology such as ScaleMP's vSMP hypervisor for clustering servers is also an interesting option for scaling. SQream is keeping quiet about its plans for now, but there are a number of different ways to do this. And remember, GPU memory is going to go up as Nvidia adds HBM 3D stacked memory to the Pascal cards, and the CUDA core count will keep going up, too.
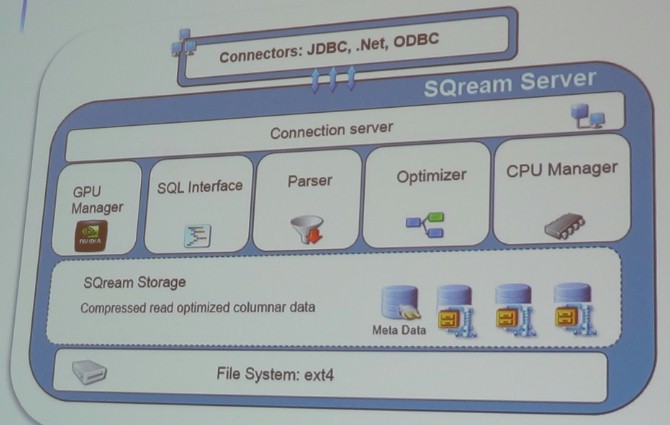
"The important thing about Analytics Engine is that we talk to the world the same way," Netzer said. "Above the hood, everything is the same, everything is standard – JDBC, ODBC, .NET. Below the hood, nothing is standard. If you are using an ETL tool like DataStage or Informatica, no problem. If you want to use Hadoop to do ETL, no problem. The bottom line, the file system, is also generic ext4, and it is a proven file system and it works well on Linux. If you need larger implementations, you can go to XFS."
The connection server in the SQream stack handles ETL or requests for queries or reports. The stack has a GPU manager, which manages the distribution of work to the GPU processors in the system, and a CPU manager, which distributes work to the X86 processors in the system. The CPU is mainly used for task scheduling and sundry tasks. The database runs on the GPUs, rather than having a database offload calculations to a GPU. To have the database run efficiently on the GPU, SQream had to build its own SQL parser, optimizer, and compiler, which was the biggest part of the work it did in developing Analytics Engine. These parts of the database were written in Haskell, which is one of a number of functional programming languages (Erlang is another popular one, developed by telecom gear maker Ericsson) and which is distinct from imperative programming languages like C, C++, Java, Pascal, and others.
The data storage for the Analytics Engine is a read-optimized compressed columnar data structure, and here is how it works:
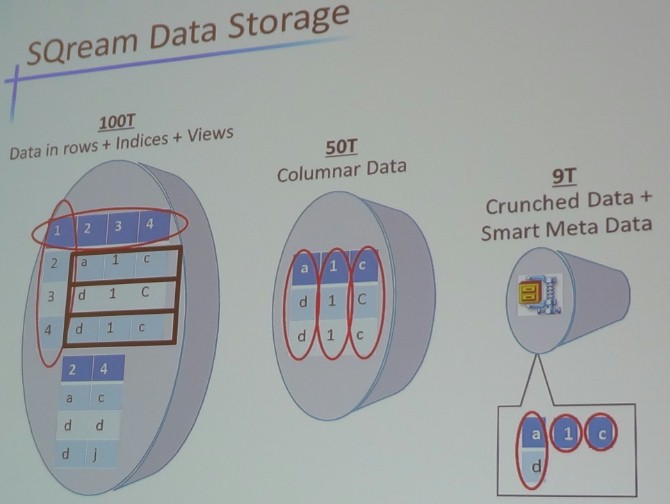
The storage, says Netzer, has a very smart metadata layer and below that is the columnar database structure that gets data compression techniques applied to it. The data stored in a relational database weighing in at 100 TB has the data stored in rows, plus indexes, for fast searching through that data, and views, a kind of virtual table the represents the results of a stored SQL query that is also used to speed up database performance. The Analytics Engine doesn't need indexes and views because it is highly parallel and running on thousands of CUDA cores. Switching to the columnar format and removing indexes and views cuts a typical relational database down to around 50 TB; sometime it is more like 40 TB or even 30 TB if the customer gets lucky. With the addition of compression and the help of metadata for organizing the table, this 100 TB database can be compressed down to around 9 TB. The Analytics Engine database does data chunking as well, so it can do data skipping, and that means you do not have to read the entire database to do certain queries. The database works perfectly fine using disk drives, but Netzer says that flash storage is useful for temporary file space during joins of big datasets.
"We are able to push 2 TB/sec on a single node, and those of you that are familiar with Hadoop, that is extremely fast," says Netzer.
The Analytics Engine database has a number of use cases aside from being a data warehouse that runs very fast. In another case, customers can take data streams such as web logs or customer data records (for the telco industry) and do queries on the data as it is streaming into a collection of SQream servers running Analytics Engine. (This is using a partitioning technique for the databases and is not a clustered instance.) This setup also allows for ad hoc queries against the data in the nodes, but again, the data is partitioned in some manner and to queries all the data sets, you have to execute the query against all the nodes and then merge the data at the end. This does not happen automatically. The SQream appliance can also be used as a backup node for online databases, and you can also run it on Amazon Web Services nodes where they are equipped with Tesla GPU coprocessors as well.
SQream has done a bunch of benchmark tests of its Analytics Engine to show off how fast it is. In one test done in its labs, it took the 100 GB TPC-H data warehousing benchmark test code and ran it. This is not an officially sanctioned TPC test result, of course, but a machine equipped with Microsoft's SQL Server did a chunk of the query work in 390 seconds, and a machine equipped with the Infobright columnar database was able to do it in 106 seconds. A two-socket Xeon E5 server with two Tesla K40 cards did it in 17 seconds.
On a star schema join with a 1.2 TB dataset, Hapyrus showed it took a Hadoop system running the Hive query overlay 1,491 seconds to run a set of queries, but Amazon Redshift took only 155 seconds to run it. SQream did the same test on an Analytics Engine appliance and it took only 29 seconds to run the query. On a data loading test, Redshift took about 17 hours to load up the dataset, and the SQream machine took an hour.
"If it takes 17 hours to load the data, I don't care about the data," says Netzer, and many enterprise customers would agree with this statement. "That is yesterday's news."
So what about real workloads? A cybersecurity firm based in Israel had a Superdome server from Hewlett-Packard with 32 Itanium cores and a set of EMC storage arrays running the Oracle 11g database; this system, not including database software, cost around $150,000. The test case was to load and analyze a massive amount of network traffic. Specifically, that was loading 6,000 customer data records per second and then doing continuous queries against it that finish under 10 seconds. The SQream system was a Dell T6700 Xeon workstation with a moderately powered GeForce GTX 680, which cost $7,000 for the hardware. Here is how the two machines stacked up on a test with 8.5 billion records, weighing in at around 17 TB of raw database size:
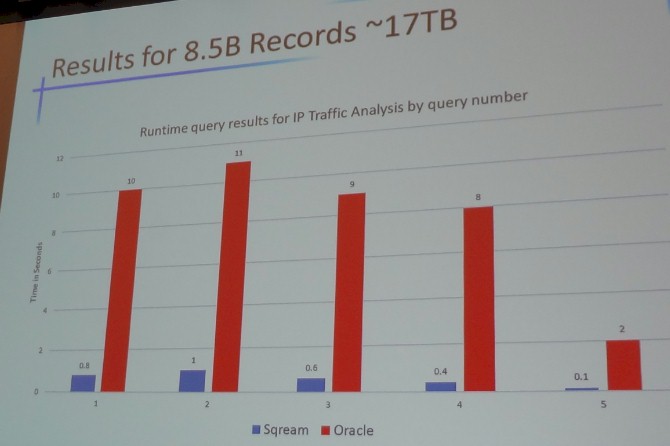
That chart is a bit fuzzy. The red columns show how long it took to run five different queries against this dataset on the Oracle system, and the blue columns show how long the same queries took on a workstation running the SQream Analytics Engine database. The queries ran on the order of 11 to 20 times faster, and with a real server with two Tesla K40 GPUs, the performance would obviously have been a lot higher. And at a cost of $15,000 for said hypothetical server, the machine would be about an order of magnitude less costly, too. This is a huge difference in price/performance, obviously.
This is one reason why Orange, the French telecom giant, is putting the SQream Analytics Engine through the paces in its datacenters right now, explained Soumik Sinharoy, senior product manager at the company who works in the company's labs in Silicon Valley.
"The challenge that we have is that we have a large user base on enterprise data warehouses, and I don't want to mention names here, but we wanted to reduce total cost of ownership, not only in execution but also in how we manage it," said Sinharoy.
The other challenge is global IP traffic growth coming from smartphones, which is expected to rise from 1,000 PB per month in 2013 to around 10,500 PB per month by 2019. The growth in Asia is going to be phenomenal. At the moment, Orange has 230 million customers worldwide, with 172 million of them being mobile subscribers, and they are generating a lot of call data records that have to be sifted and sorted for various reasons. The name of the game for mobile phone operators is to provide services and software to customers that make them happy, and to try to figure out when they are not happy so a problem can be fixed before they change to another carrier. (The old adage that it is ten times harder to get a new customer than it is to retain an existing one is definitely true with smartphones.)
The call data record volume at Orange is exploding, running at around 60 billion per month right now in France alone and expected to grow to 150 billion per month by the end of this year, driven by the launch of 4G networks in most major cities in France.
"This is going to be pretty challenging," said Sinharoy. "Today, the state-of-the art, leading enterprise database running on enterprise data warehousing appliances are not going to scale. We want a solution for the future, and SQream is one of them."
The biggest challenge that Orange has with the CDR databases is when it needs to run multidimensional queries, such as when it has three or four months of customer data for an application, it can take 25 to 32 hours for these queries to run. Loading up the data also takes time. On one test that Orange did, which scanned and joined 35 billion customer data records with a 30 million subscriber database, it took a "massive amount" of hardware investment for the data warehouse, did not scale well, and required manual processes for optimizing the software. It took the Oracle database 60 hours to load 300 million records, while the SQream appliance (again, one node with two GPUs) took 9 hours. In terms of price/performance, the difference was a factor of 50, according to Sinharoy.
Here is what Orange's query benchmark tests, pitting SQream against "a leading enterprise data warehousing solution," not Oracle as shown in the chart (it was a typo), showed on a mix of six queries:
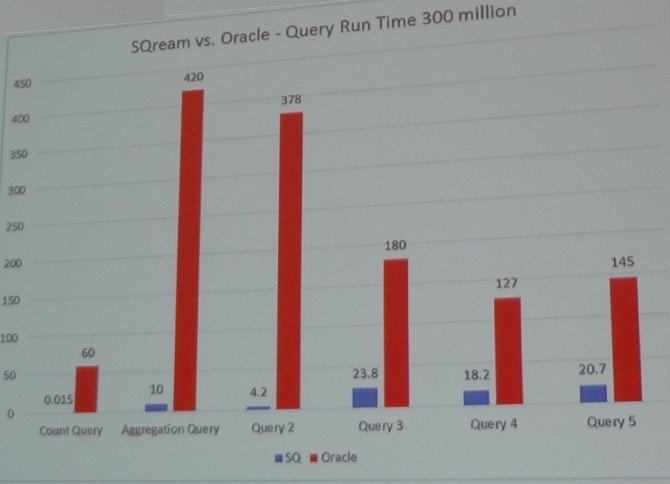
In addition to the count and aggregation queries shown, Query 2 was to map the load on the network by hour, total call and minutes. Query 3 was to map by hour and call type, and break down the network load by call type, SMS, data and voice. Query 4 was to map the load on the network in a specific time, and Query 5 mapped the load on the network in a specific time for voice, SMS, and data services.
Everyone in the room suspected that this comparison pitted a SQream appliance against a Teradata enterprise data warehouse machine, a full rack of stuff.
Analysts briefed ahead of the GTC event saw a direct comparison between SQream and Teradata for different Orange workloads, with the Teradata EDW having 14 servers and having 168 cores with 67 TB of solid state disks to make it peppy. This test was to do queries against four months of IP traffic merged with 4.3 billion call data records, and the SQream machine only had one GPU and 3.2 TB of flash. The EDW cost $6.3 million and the SQream box, including the Analytics Engine software stack, cost $250,000. The SQream machine did the database work a little bit faster on this particular test, and look at the difference in price, even with that hefty software bill for the Analytics Engine. (Call it $230,000 with $20,000 for hardware as a ballpark).
The SQream Analytics Engine software will be available in July and is being tested at a number of customers right now.






