



Maersk Oil Tests Reservoir Simulations On AWS
The great thing about cloud computing is that it doesn't cost very much to test out an idea. While we expect developers of Web applications to be monkeying around on the clouds, testing out code and business models, energy companies are probably the last thing that anyone would expect to move applications to the public cloud. But as a thought experiment, Danish energy company Maersk Oil has run some reservoir simulation tests and found that it is technically feasible.
The results of Maersk Oil's tests were published in a paper recently at the SPE Intelligent Energy Conference in Utrecht, The Netherlands, and demonstrate that for a certain style of reservoir modeling, moving to cloud infrastructure can work. Unlike some of the larger oil companies, Maersk Oil does not write its own reservoir modeling applications but rather uses the Eclipse suite from Schlumberger. In this case, the study was done by the Maersk Oil officer in Doha, Qatar, which has a 40-core license to the Eclipse reservoir modeling.
Maersk Oil is a $9.1 billion unit of Danish conglomerate AP Moller-Maersk Group, and was set up in 1962 to search for oil in the North Sea. Maersk Oil is an independent oil and gas producer and does about 600,000 barrels per day in oil and up to 1,000 million cubic feet per day in natural gas. The Maersk Group, as the conglomerate is generally known, employs 89,000 people and had $47 billion in sales last year; it operates a fleet of 600 cargo ships, the largest such fleet in the world, as well as 57 ports and container terminals, the Maersk Oil unit, and an independent oil and gas drilling company. The oil and gas subsidiary has computing facilities at its headquarters in Copenhagen, as well as in Aberdeen, Scotland and Houston, Texas. All three have larger clusters than the one in the Qatar office, according to Tom O'Reilly, head of server systems in Qatar, who crafted the cloud test along with his peers.
Generally speaking, there are two approaches to reservoir simulation, O'Reilly explained to EnterpriseTech. The probabilistic approach takes all of the seismic data and tries to render an oil or gas reservoir underground in one fell swoop with all possible scenarios. With the deterministic approach, geophysicists and reservoir engineers use their own expertise and judgment and focus in on a specific portion of the reservoir and pick the most likely scenarios for the reservoir and then model these. Eclipse is popular, but it does not scale well, and therefore it is more suited to the deterministic approach. According to O'Reilly, after about 32 cores any incremental amount of compute that is thrown at Eclipse does not make the application run appreciably faster. As such, it lends itself well to the deterministic approach to reservoir modeling, and reservoir engineers run hundreds of jobs, each representing different scenarios, to come up with an idea of what is going on deep in the earth.
"Maersk Oil uses the deterministic approach in general because they think it is more valuable to use expertise rather than throwing volume at it," says O'Reilly. "The number of cores that you need to run at any one time is much lower. However, some of the reservoir engineers wanted to think about how to do a more probabilistic approach and how they might scale up to that. We could not do that internally because the cost would be too large, and so we tried to do it in the cloud."
Not only did Maersk Oil simulate a baby Eclipse cluster in the cloud that could run the reservoir simulations, but it also went one step further and simulated a remote office from that cloud that would simulate what it would do to create that office without any of its own infrastructure as the four offices it operates near its fields have today. (If you are going to take the cluster to the cloud, why not the whole office and do away with everything but end user compute devices?)
To that end, Maersk Oil's techies set up a virtual field office in Amazon Web Services' UK region and linked it to processing capacity running in Amazon's US East Coast region, where the reservoir simulations ran. Like this:
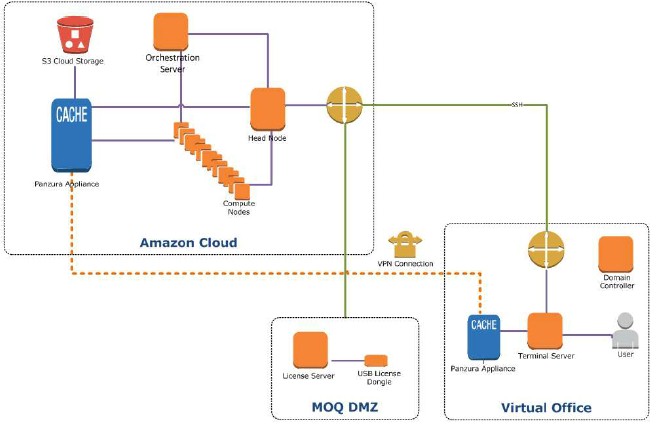
Each site had a virtual private cloud with a virtual private network linking them, and to facilitate the high speed data movement that would be required from the field office to the remote cluster, Maersk Oil uses the Quicksilver cloud storage controller, from Panzura, which is installed in Amazon's facilities, to convert its S3 object storage into something that looks like a NAS server sitting on a local network with a CIFS or NFS interface. The Panzura appliances also act as a cache for S3 storage, speeding up uploading and downloading of files. Schlumberger provided Maersk Oil with ten licenses to the Eclipse core simulator and 64 licenses to the Eclipse Parallel/MR code as well as a license dongle, which was hooked virtually into the AWS capacity. The latter bit allows for the Eclipse code to run on multiple cores within a system. Specifically, it allows you to run one scenario across multiple cores, different scenarios each with their own core, or a combination of the two. The head node in the virtual Eclipse cluster was C3.xlarge instance on AWS, which has a 10 Gb/sec Ethernet controller, two 40 GB solid state drives, and four virtual CPUs at a cost of 21 cents per hour. The compute nodes had eight virtual CPUs, and the test ran on eight nodes for a total of 64 cores. O'Reilly was not sure what nodes were used here, but they cost 27 cents per hour, he said.
The simulation that Maersk Oil ran was for the Halfdan field in the North Sea, and it modeled oil, gas, water vapor, dissolved gas, and brine flows in that field, which had up to 150 wells being simulated. The simulation was for a time period spanning from December 1996 to December 2012. On its internal BladeSystem blade server from Hewlett-Packard, the Qatar office could run this simulation in 19.6 hours. It took 7.7 hours on four cores in the blade and 5.7 hours on eight cores in the blade. Here's how the simulated cloud stacked up:
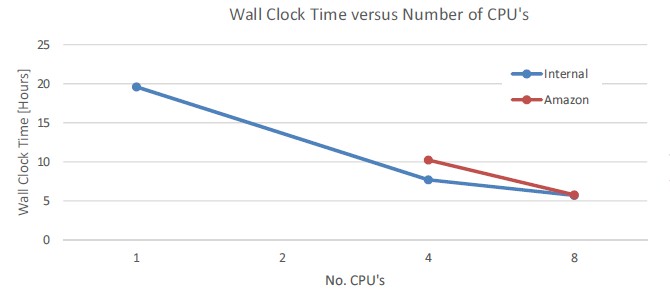
As you can see, the virtual instances on AWS had roughly the same performance running this scenario in Eclipse as did the actual HP blade server. While the internal iron at the Qatar office of Maersk Oil can only scale up to eight cores in a single system image, Amazon's cx.8xlarge instances can scale to eight virtual CPUs, and should, in theory, reduce the time to complete the simulation considerably. Even more interestingly, O'Reilly said that the company had played around and figured out it could create a virtual cluster and submit more than 100 scenarios to it at the same time, splitting the difference between the probabilistic and deterministic approaches. With the fatter nodes and the many jobs submitted at the same time, Maersk could radically speed up the time it takes to do reservoir simulation.
There are only two catches. First, the Eclipse software from Schlumberger is only available on a perpetual or annual license on a per-core basis; it is not available on an hourly basis with utility-style pricing. Moreover, the hardware compatibility matrix for Eclipse is not very deep – it has ten different servers on it, and Amazon's EC2 virtual machines are not on that list. So, officially, running Eclipse on EC2 is not an option.
"We wanted to prove that it can be done in a virtual environment and in a public cloud environment and with performance comparable to what you could get internally," says O'Reilly. That said, don't expect Maersk Oil and its competition in the energy sector to jump wholly to the cloud any time soon. "Oil and gas will probably be one of the last industries to do that. There is a lot of fear and uncertainty about what data can be kept where."
Just like Amazon had to create GovCloud with extra security and isolation from other parts of its worldwide network, perhaps the cloud company will create EnergyCloud and distribute resources to the major oil and gas producing regions of the world. Or, it could go one step further and build private versions of the AWS cloud for energy companies, much as it is doing for the US Central Intelligence Agency, for each oil-producing region. Companies and countries have strict rules about the movement of seismic and reservoir data outside of their domains, and this might be the best compromise. (The Halfdan seismic data used in the cloudy reservoir simulation is in the public domain, so there was no security risk.)
All that said, getting energy companies to share resources might be tough, no matter how low the cost is, particularly for those energy companies that keep their clusters loaded up with jobs 24 hours by seven days. It will be interesting to see what develops.






