



ARM Server Chips To Scale To 32 Cores And Beyond
The first wave of 64-bit ARM server processors are just coming out of the fabs from AMD and Applied Micro, and ARM Holdings, the company that licenses the ARM architecture, is cranking up the coherent interconnect at the heart of its system-on-chip designs to push even higher scalability in the not-too-distant future.
As with core designs, companies can either license this enterprise-grade Corelink Cache Coherent Network, as the interconnect is known, or create their own. Given the feeds and speeds of the Corelink designs, ARM licensees might want to think about cheating off this bit of homework and differentiating elsewhere.
At the ARM Tech Day last week in Austin, Texas, Mike Filippo, lead architect for CPUs at ARM Holdings, walked EnterpriseTech through the intricacies of the interconnect that glues all of the elements of an ARM server processor together. Corelink, which is based on an interconnect architecture called AMBA 5 CHI, is every bit as sophisticated and capable as anything that chip makers for large systems have developed. But server customers will always want more, and so ARM has plans to bring more cores and bandwidth to bear in future chips. There is even a remote possibility (pun intended) of extending Corelink to provide some measure of cache coherency across multiple ARM SoCs, but ARM Holdings is making no promises there. And significantly, even if ARM Holdings does not extend Corelink to glue multiple SoCs together, the openness of the architecture means that those companies that do have expertise in creating NUMA systems could bring their own intellectual property to bear to make that one of their own differentiators.
The Advanced Microcontroller Bus Architecture has been around since 1996 and has evolved from a system and peripheral bus to one with coherency extensions since version 4 that allow for multiple cores to share high level cache as well as main memory in a single system image. Memory controllers, L3 cache, network interfaces and various I/O controllers all hang off the same interconnect ring in the AMBA 5 Coherent Hub Interface (CHI) specification. The Corelink CCN-5XX family of interconnects implement this specification. Other vendors can adopt the AMBA 5 CHI specification and create their own means of implementing the spec. The coherency in the Corelink is not just for the ARM CPUs, but also can be applied to GPUs, DSPs, and other kinds of accelerators that hang off the interconnect. The ARM cores do not all have to be the same type, either, and in fact the Corelink interconnect is what enables the mixing of wimpy and brawny cores on SoCs, what ARM refers to as big.LITTLE.
ARM started down the server road in earnest in 2010, explained Filippo, when the company decided to also push harder into the networking space. Corelink has been a big factor in the success of ARM moving into networking equipment, displacing MIPS and PowerPC processors and giving X86 products from Intel and AMD a run for the money, too. The first Corelink on-chip interconnect debuted last year, and it was called the CCN-504. The four in the name refers to how many ARM core clusters can be supported on the die. Each core cluster in the ARMv8 architecture (also called AArch64 and referring to 64-bit processing and memory addressing) can have four separate cores hanging off the interconnect bridge. In this case, licensees can choose the 32-bit Cortex A15 cores or the 64-bit Cortex-A53 or Cortex-A57 cores. So the CCN-504 can support between four and sixteen cores, depending on if each clusters have one, two, or four cores.
The CCN-504 design has a 128-bit bus width and runs at core clock speed, and the L3 cache ranges from 8 MB to 16 MB. The CCN-504 has two DMC-520 main memory controllers, which have two channels each, and bandwidth using DDR4 memory running at 2.67 GHz approaches 50 GB/sec. In addition to the CPU and memory controller ports, the Corelink CCN-504 has a single NIC-400 network interconnect controller that can have SRAM, flash, PCI-Express, or general-purpose I/O hanging off it. The Corelink MMU-500 memory management unit is a separate controller that hangs off the interconnect that presents virtualized I/O and memory to it. This feature enables for a more lean and mean implementation of server virtualization. There are up to eighteen AMBA interfaces that can exploit this uniform system memory. The interconnect offers up to 1 Tb/sec of non-blocking system bandwidth across the components. (Chip maker LSI, which has announced a chip that implants the CCN-504 interconnect in its Axxia 4500 network processors, is using a 28 nanometer processes, presumably etched by Taiwan Semiconductor Manufacturing Corp.)
The CCN-504 was last year’s story, and at the ARM Tech Day, what Filippo wanted to show off was the CCN-508, which will be available in 2015 and which is timed to come to market in conjunction with 16 nanometer FinFET (3D transistor) processes for the A53 and A57 cores from TSMC. Here’s what this monster looks like:
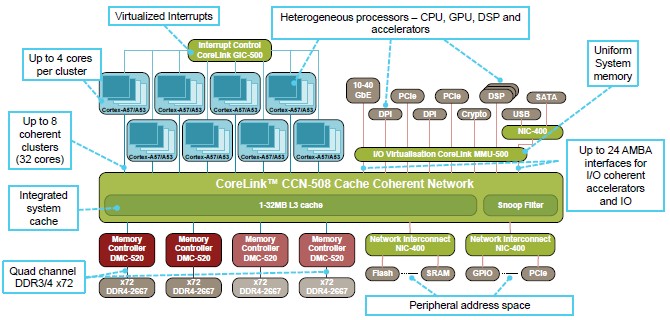 Basically, the CCN-508 implementation of Corelink doubles up the components. Master devices are shown at the top of the chart and slave devices at the bottom; the slave I/O devices do not have coherent access to cache and main memory.
Basically, the CCN-508 implementation of Corelink doubles up the components. Master devices are shown at the top of the chart and slave devices at the bottom; the slave I/O devices do not have coherent access to cache and main memory.
There are eight CPU interconnect bridges, allowing for between 8 and 32 cores to be on a single die. At core speeds, the Corelink interconnect will deliver a peak bandwidth of 2 Tb/sec and sustained usable system bandwidth will be on the order of 1.6 Tb/sec. The setup has four memory controllers and two NIC-400 network interconnects to balance out the doubling of cores in the system. The MMU-500 I/O virtualization circuit has up to 24 AMBA interfaces for other I/O, which is only a 33 percent increase over the CCN-504. Scaling I/O from other components on the chip is not unusual in X86 processor designs, so this is not surprising.
Those peripherals on the top of the chart have coherent access to memory, but they have to be enabled to speak AMBA to access it. So, for instance, a GPU from Nvidia or AMD could have a link very much like Nvidia’s NVLink or IBM’s CAPI to have one shared virtual memory space for both CPU and GPU across the interconnect. Filippo also said that ARM expected to enable the Heterogeneous Systems Architecture (HSA) hybrid CPU-GPU compute and shared memory architecture created by AMD for its own ceepie-geepies in the ARM chips at some point, but said it was still “early days” for HSA. “We are one of the members of HSA, and we agree with the concept, and we will have greater support for that as we release new products,” Filippo added.
The important thing to consider is that all of this coherent memory sharing between CPUs and accelerators has to be done on a single die at the moment. “Off chip acceleration will happen when we get to chip-to-chip communication that is currently being looked at for a follow-on to AMBA 5 CHI and Corelink CCN-5XX,” explained Filippo. “Today, we do not support fully coherent off die.”
A word about the Cortex-A57 cores, which are the high-end cores aimed at server workloads, if you are not familiar with them. The cores in each cluster have 48 KB of L1 instruction cache and 32 KB of L1 data cache, plus an L2 cache of 512 KB per core. Up to four cores can be in a cluster for either the CCN-504 or CCN-508 interconnects. The L1 instruction cache has parity checking and the L1 data and L2 caches have ECC scrubbing.
There are a couple of things to note about the Corelink CCN-508. First, as Filippo explained it, that L3 cache is not so much a shared L3 cache for processors as it is an I/O cache for all devices, including the processors. Second, the Corelink has a fully distributed architecture, by which is meant that arbitration and routing functions in the ring, L3 cache segments, I/O controllers, and memory controllers are all segmented and distributed across the ring. (Technically, the CCN-508 has two 128-bit bi-directional rings to double up its bandwidth.) This means bottlenecks are reduced and the chip doesn’t have hotspots. And third, this approach means ARM can take a cookie cutter approach to building out and scaling down SoCs. At a 2 GHz target clock speed, the CCN-508 interconnect provides more than 75 GB/sec of bandwidth to main memory. At around 40 GB/sec per AMBA port, the I/O and accelerator bandwidth peaks at a little over 300 GB/sec. The design delivers around 360 GB/sec of peak and 230 GB/sec of sustained bandwidth from the interconnect into and out of L3 cache. The memory controller supports DDR3, DDR3L, and DDR4 main memory, and has quad channels. DDR4 memory will initially support 2.67 GHz speeds, but the DMC-520 memory controller can ramp to 3.2 GHz speeds. These memory channels deliver more than 21 GB/sec of bandwidth running at the target clock speed.
That L3 cache, by the way, has a number of different power states as well, including a partial power down that turns it from a 16-way associative cache to an eight-way cache with half the capacity. The L3 cache can have its memory powered down and still act as a conduit to main memory and also has an active retention mode that can wake the cache up in five clock cycles. CPU cores can also be shut down and there is extensive clock gating and retention on circuits on the SoC to conserve power when components are not needed by the software.
But wait, that’s not all you get. Take a look at the Corelink interconnect roadmap:
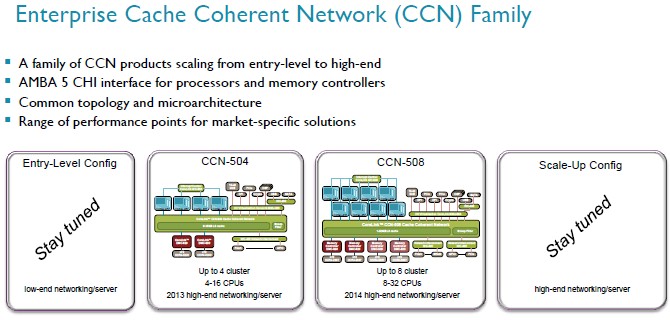
It doesn’t take a supercomputer to see the pattern here. Filippo said that ARM was working on a cut-down variant of the Corelink interconnect aimed at low-end servers and networking devices, and an even larger scale up version targeting even larger workloads with more of everything.
“You can expect an announcement either later this year or early next year of an entry level config that will be smaller than this guy,” said Filippo pointing to the CCN-504, “and a scale-up config that will be larger than this guy,” pointing to the CCN-508.
We would guess there will eventually be a CCN-502 with two CPU clusters, one memory controller and maybe a dozen AMBA ports plus a single NIC-400 network interface. And at the top-end, a CCN-516 would be a doubling up of the CCN-508, offering sixteen CPU clusters or a maximum of 64 cores on a die. It seems likely that such a beat might not be able to run the interconnect ring at core clock speed, so it is hard to guess the bandwidths. But such an interconnect, which will also be implemented in 16 nanometer processes according to Filippo, would be the basis of a formidable chip indeed.
With a scalability appetite that is not easily sated, EnterpriseTech asked about the possibility of supporting fully coherent communication off the die for processor-to-processor links, and Filippo said that in theory it would use the same modified AMBA links as bringing in off-die coprocessors. How and when this might happen remains to be seen. But there are many interesting ways this might be accomplished. A 64-core ARM beast available with two, four, and eight sockets in a NUMA configuration is a very interesting machine to contemplate. That would truly be big.LITTLE iron.






