



How Facebook Autoscale Cuts Cluster Electric Bills

The reason why online retailer Amazon started its cloud computing unit was not just because it wanted to break into a business selling raw compute and storage capacity to developers who had to work on a slim-to-none capital budget. That was an after effect. What drove the creation of AWS was the realization that turning a server off once you have it in a datacenter does not make economic sense and that you need to find work for those servers to do in order to justify their existence.
Not everyone can start up a cloud computing business with clever pricing and utility models that move customers into the utilization valleys and off the peaks, and until Facebook decides to do that, it will have to try to make the best use of the iron it has to boost the efficiency of their operation. To that end, Facebook is showing off a new system management program it has created for its own datacenters called Autoscale. As the name suggests, Autoscale is a load balancing system that is designed to run Facebook's infrastructure in a way that it burns less juice and generates less heat, which saves on the electricity bill. Basically, it is an admission that an idle server is better than not having enough capacity to handle peak loads, and that saving energy is better than not doing it at all.
Qiang Wu, infrastructure software engineer at Facebook, says in a blog post that Facebook has tried a whole bunch of different ideas out to conserve power, including power modeling and profiling, peak power management, and energy-proportional computing. The latter is very interesting in that it involves creating machines that scale up their power consumption more linearly as work is loaded up on them. (The typical server from a few years back is running at somewhere between 10 and 50 percent of utilization, according to Google, and yet it is most energy efficient running up close to 100 percent of capacity and energy efficiency falls down to 20 percent when the processing capacity is a low as 10 percent. This would at first seem to argue for turning some machines off and moving workloads onto other machines.
However, many workloads do not consolidate easily onto shared machines, and virtualization of any kind imposes performance penalties. So Facebook has to come up with other means to save energy in its vast server farms. This is what Autoscale is attempting to do.
Up until recently, Facebook's Web server farm, which handles billions of requests per day as people indulge in their social media lives, used a plain vanilla round robin method to assign Web page request processing to as surfers came into its network. Generally, speaking, as Wu explained in the blog, every server in the farm gets about the same number of page requests and eats up about the same amount of CPU for similar machines. Energy efficiency across the fleet drops as utilization drops. To give you an idea of the range, when a Web server is sitting there idle at midnight, as many machines in its fleet are, the machine still eats about 60 watts. When it is running a small workload, the power consumption more than doubles up to 130 watts – and here's the interesting part – when the Facebook Web server is running at a medium workload, the power consumption only goes up to 150 watts. The idea, then, is to get machines to run at a medium level or slightly higher for the purposes of energy efficiency, and then let the servers in the Web farm that are not doing heavy work either sit idle or do some kind of other batch processing. (As Facebook scales around the globe, it will find less and less idle time available on its fleet, and it will have to come up with a new algorithm to replace Autoscale.)
"Though the idea sounds simple, it is a challenging task to implement effectively and robustly for a large-scale system," says Wu.
The way Autoscale works is similar to many other controllers in hyperscale computing. A central controller with decision-making logic gathers up telemetry from the server fleet, in this case relating to CPU utilization and request queue depth for each machine, and based on this information it tells the existing load balancers the ideal size of the pool of active machines to support the workload and run them at a medium load. (You can't push it up to peak load because at some point, latencies build up in the server farm and performance suffers. Having said that, as the IBM mainframe demonstrates, there is a way to tune a machine for a very specific workload and have it run at near 100 percent utilization for many years at a time. However, a mainframe may be ten times as efficient as a cluster of fat Xeon server, but it also costs more than ten times as much.)
Here is what the relationship between Web server farm requests per second (RPS) looks like plotted against CPU utilization, which has been normalized to the daily maximums:

As you might expect, when most of us in the United States are sleeping (or are supposed to be), the workload on the Web farm at the closest Facebook datacenter in the nearest time zone drops quite a bit. Facebook does not want to give out precise numbers about how many machines it mothballs using Autoscale, so this chart below is normalized against the maximum number of machines that were put into an idle state by Autoscale during a one day cycle, and it has the sine wave shape that you would expect:

All of the servers were fired up during peak hours, as you can see around that flat spot in the line between around 10:15 am and 1:15 pm where this cluster was located.
Now, here is where the effect of Autoscale becomes really apparent. In the chart below, the red line is the power consumption of a cluster (it is not clear how many machines it is, but probably a pod that is somewhere around 5,000 nodes or so) over the course of a day. The blue line shows the power consumption with Autoscale turned on and many of the machines pushed into an idle state when the Web serving load is light.
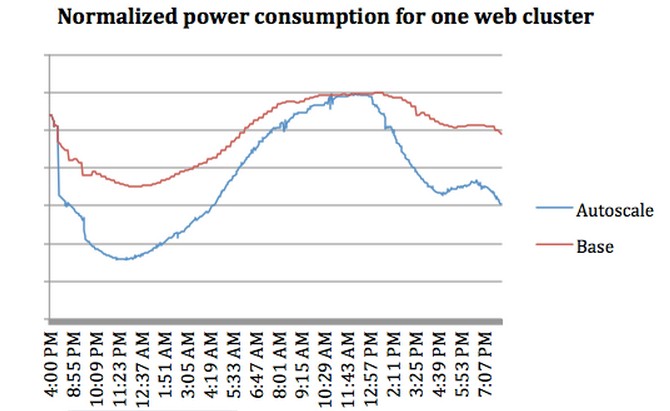
During that late morning, early afternoon period, the Autoscale load balancer doesn't save any power, but during the period when there are fewer Facebook surfers, generally around midnight, the power bill drops by 27 percent. Average it out over a full day, and the power savings works out to somewhere between 10 and 15 percent in the early production use of Autoscale.
It will be interesting to see how Facebook weaves Autoscale into disaggregated servers, which will attempt to break the processing, memory, and storage components of server nodes free from one another and allow them to scale up and down independently from each other. It is very intriguing to think about how a system might try to get work done faster by scaling up necessary components quickly and getting them back to idle power fast and leaving unnecessary components idle. Again, it is always better to run components at a mid-to-high load if you can, if you are optimizing for energy consumption, but in a world where the workload has such peaks and valleys, this is not possible without bringing in a lot of outside work during the valleys and getting rid of it during the peaks.






