



How Microsoft Is Using FPGAs To Speed Up Bing Search
Microsoft has dug in for a long and perhaps uphill battle with search engine juggernaut Google, which has three times the reach in search. That means Microsoft has to deploy whatever technology it can to make its Bing search engine both faster and more accurate. To that end, Microsoft will be rolling out artillery in the form of field programmable gate arrays (FPGAs), which it is putting into the servers that underpin its Bing search service.
In a presentation at the recent Hot Chips 26 conference in Silicon Valley, Andrew Putnam, a senior research hardware development engineer in the Microsoft Research Technologies lab, talked about how Microsoft had decided to give FPGAs a shot at boosting Bing. It took a few tries and three years of development to get the right kind of integration between the CPUs and the FPGAs that matched the way the various Bing services function. Having successfully tested out the idea in a research setting on a fairly large cluster, Microsoft will be deploying FPGA-accelerated nodes for the Bing service in 2015, which is good news for both Altera, its FPGA partner, and Quanta Cloud Technology, one of its server manufacturing partners who worked with Microsoft on the prototype systems.
Like everyone in IT, explained Putnam, Microsoft is wants its infrastructure be as homogeneous as possible and yet at the same time have specialization that allows for its particular software routines to be accelerated by orders of magnitude. IT organizations have been able to get a high degree of homogeneity by adopting X86 servers, and the fact that Microsoft's Windows Server platform, which it uses underneath all of its cloudy services, is only available on X86 iron makes the choice easier.
The backwards compatibility of X86 systems allows Microsoft to have a fairly aggressive server refresh cycle, which keeps its machines as close to the leading edge as is economically practical. Putnam explained that Microsoft changes its services monthly, which is something you can do with software, while servers are purchased on a staggered, rolling basis with machines having a three-year maximum life span. By doing it this way, Microsoft does not have to pay for hardware maintenance beyond the three-year warranty that is common with servers. Half-way through their economic life in Microsoft's datacenters, the machines are repurposed. Given that a server is not necessarily tied to a specific workload, Microsoft wants to have as few variations as possible.
Despite all of that, specialization in the form of application acceleration is coveted, and this chart below, which plots the energy efficiency of an operation performed by a particular type of compute device against its flexibility:
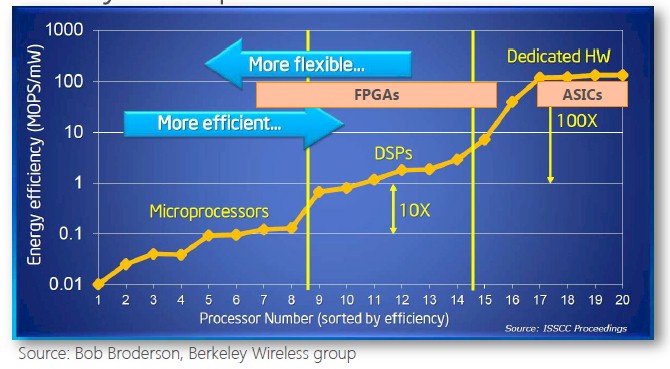
Microprocessors like X86 chips from Intel and Advanced Micro Devices are the most flexible and are billed as general purpose computing platforms. The term most commonly used to describe X86 machines is industry standard servers, and that is because the X86 architecture has become a de facto standard – at least until ARM chips get more of a foothold in the datacenter.
Microsoft has plenty of money and could just create specific ASIC chips to accelerate its Bing search functions, but if the software changes, then that part of the hardware stack could end up being useless in terms of running software while at the same time burning power and possibly breaking and causing a server to fail. With search acceleration functions done in an FPGA, by contrast, the device can be reprogrammed to support new algorithms as they are created and should the machine be repurposed to an HPC cluster, in Putnam's example, the FPGA could be reprogrammed to be an accelerator to goose mathematical routines used for modeling and simulation workloads. The FPGA doesn't become a boat anchor, and it rivals ASICs in terms of energy efficiency per operation.
Putnam did not put GPU coprocessors or parallel X86-based coprocessors like Intel's Xeon Phi on this chart, but obviously both could be employed to accelerate workloads. But after an initial prototype from 2011, which used a large PCI-Express card, Microsoft chose a server architecture that could not easily integrate such large and hot coprocessors into their enclosures. Including its own custom FPGA card.
Here is what the first FPGA card in the Project Catapult effort looked like:

This prototype FPGA accelerator card had six Virtex-6 FPGAs from Xilinx linked together by a PCI-Express switch from PLX Technology (now part of Avago Technologies). Microsoft plugged three of them into a Supermicro SuperServer designed to accommodate three Tesla GPU coprocessors from Nvidia, which had two six-core Xeon 5600 class processors. (This was a few years ago, remember.) One of these FPGA nodes did the Bing search scoring for a 48-node server pod, and was linked to the nodes by four 10 Gb/sec Ethernet ports.
While this Catapult prototype certainly accelerated some Bing search functions, there were a number of issues with this approach. For one thing, the FPGA node was a single point of failure in the application for the 48 nodes in the pod. Also, by having two different kinds of devices in the rack, it is more complex to cope with power and cooling. Another problem is that any time any application needed to communicate with the FPGAs, it had to deal with network latencies. And finally, if an application needed to span more than six FPGAs, there was no way to do that, even though three cards shared a single server enclosure. (The FPGAs were linked on the card by a PCI-Express switch, but not across the node by any kind of switching or direct link.)
After the Catapult prototype, Microsoft Research went back to the drawing board with its colleagues at the Bing division, and laid out a few rules for how a next-gen FPGA acceleration initiative would look. First and foremost, the FPGAs had to plug into an existing Microsoft server, and in fact, the one that was chosen is the Microsoft Open Compute Server that the company revealed early this year and donated to the Open Compute Project. This machine has 24 half-wide two-socket X86 server sleds that fit in a 12U enclosure, and the node has just enough space for a half height, half length PCI-Express 3.0 peripheral card at the back of the sled. A GPU accelerator can't fit in this space, Putnam explained, but it is just enough space to cram in a single FPGA and some memory for it onto a mezzanine card to snap it into the node.

Being at the back of the server sled, this mezzanine area gets a little warm, since air has moved over disk drives, memory, and a processor before it hits the FPGA. We are talking 154 degrees Fahrenheit (68 degrees Celsius). This particular node has two eight-core Xeon processors running at 2.1 GHz (nothing too hot) and 64 GB of main memory (again, nothing crazy), which are fronted by four 2 TB disk drives and two 512 GB solid state disks. The server node has a 10 Gb/sec Ethernet port and hooks to power and networking wirelessly through ports in the back of the sled. This space is probably too hot for a GPU coprocessor, and in fact one of Microsoft's restrictions was that the FPGA had to draw all of its power from the PCI-Express slot and it had to draw less than 10 percent of the power for the whole server node, or no more than 25 watts. The FPGA setup had to work without modifications to the existing network, not increase the hardware failure rate, and add no more than 30 percent to the cost of the server node. Microsoft also came to the conclusion that it needed a separate fabric to link the FPGAs to each other so they could share work.
The Catapult FPGA accelerator card that will be put into production will be evenly distributed across server nodes in the Bing search engine infrastructure, one per node. This time around, Microsoft is going with a Stratix V GS D5 from Altera, which is an FPGA digital signal processing blocks and 14.1 Gb/sec transceivers already set into the device. This particular device has 1,590 DSP blocks and 2,104 M20K memory blocks (for a capacity of 39 Mbits) and 36 of those transceivers. The mezzanine card has a 32 MB configuration flash and 8 GB of DDR3 memory running at 1.33 GHz on one side and a PCI-Express 3.0 x8 direct connector to the Open Compute Server node.

The FPGA coprocessor also has eight lanes going out to Mini-SAS SFF-8088 connectors, with two ports on each mezzanine card. Microsoft had two sets of cables specially made, with one implementing a ring with six SFF-8088 connectors and another with eight connectors on a ring. With the six-adapter cable, the six FPGA cards in six adjacent server nodes in the Open Compute Server chassis are linked to each other with one set of Mini-SAS ports (this is the so-called East-West traffic in the FPGA fabric). Then the eight different groups of FPGA nodes in a 48-node pod are linked to each other using that eight adapter cable. (This is the North-South traffic in the FPGA fabric.) Technically, Putnam said that this was a 6x8 torus interconnect in a 2x24 server layout. Those SAS links between the FPGAs run at 20 Gb/sec and are completely independent of the 10 Gb/sec Ethernet links that lash the Xeon nodes together. In other words, if an application needs to grab 48 FPGAs at once, it can.
The document selection service that runs as part of the Bing search engine, which finds all documents that contain a particular search term and filters documents for page ranking, still runs on the Xeon processors in the Bing clusters. But the ranking services, which computes scores to see how relevant each document is for a particular search term and which computes the page ranking scores for pages, has been ported to the Catapult FPGA coprocessors. This ranking function is broken into three parts: feature extraction, free-form expressions, and machine learning scoring.
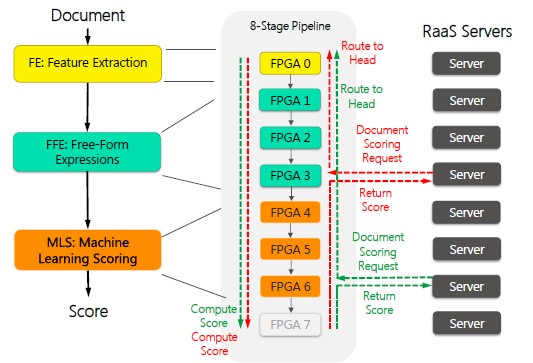
The feature extraction takes the items in a search and counts how many times they are found on a particular compressed Web page, and it takes about 4 microseconds to extract about 2,600 features in the FPGA compared to about 600 microseconds to do the same amount of work on an X86 processor with the code written in C++. The free-form extraction is done by special "soft core" processors that are created on the FPGA from logic circuits. Each of these units has four hardware threads per core, and six cores share a common arithmetic logic unit. Ten of these are clustered on a single FPGA for a total of 240 hardware threads. Here's what the rank as a service part of the Bing search engine looks like, conceptually:
Microsoft took the second iteration of its FPGA acceleration for the Bing search service and created a cluster with 1,632 nodes, and the results were encouraging enough that Microsoft is going to be rolling out the Catapult FPGAs into production Bing datacenters in early 2015.
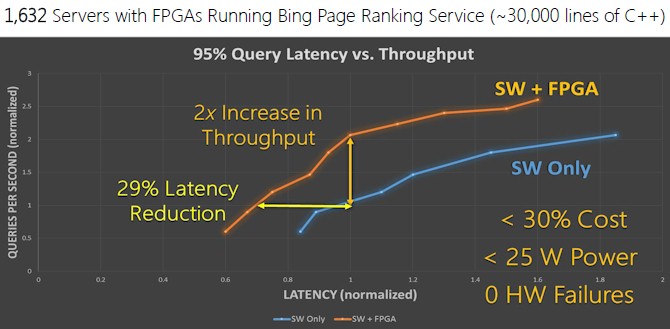
Running the Bing page ranking service, the FPGAs running portions of the service combined with those still running on the X86 iron delivered twice the throughput and reduced the latency of the ranking work by 29 percent compared to just running the whole ranking service on X86 iron. What this means for Microsoft is that it takes half the number of servers to run the ranking service as it did in the past.
Like most companies deploying FPGAs, Microsoft wants the programming to be easier and compile times for FPGAs to be faster than it is. Microsoft would also like improved floating point performance on the FPGAs as well as faster and more efficient DDR3 memory on the chips.
It will be interesting to see what Microsoft does when Intel launches its Xeon-FPGA hybrid, which it divulged it was working on back in June.






