



Banks Want Infrastructure That Is As Smart As Applications

Only a few years ago, if you went to the HPC On Wall Street conference in New York, all of the talk was about low latency and high performance. There were a couple of reasons for that, the first being that high frequency trading was much more prevalent and companies were netting much more profit from it than they are today. Moreover, with so many security breaches at large corporations and CEOs losing their jobs over it, everyone is starting to focus on security. Financial services firms are also trying to figure out ways to integrate their disparate silos and bring some order to the workflows that represent their applications.
That was the central theme of the opening keynote at this year's HPC On Wall Street event. Representatives from Cisco Systems, which provides network and compute; MapR Technologies, which provides a Hadoop distribution with lots of add-ons and a homegrown file system that is better than HDFS in many ways; Splunk, which provides data ingestion and visualization tools; and Tresata, which provides predictive analytics software that chews on big data were all on hand to talk about the issues financial services firms are facing and how an integrated approach from their companies could solve many network issues, not just run risk analysis and other analytical applications. The idea is to bring an integrated approach to networking and big data to both the infrastructure and the applications that run on the infrastructure.
As you might expect, Cisco came on strong with its Application Centric Infrastructure (ACI), which it launched last November in its high-end Nexus 9000 switches and which will eventually be cascaded throughout its switching. With ACI, Cisco is essentially baking software defined networking into its ASICs and abstracting everything you know about an application into a policy template, which in turn drives the dynamic configuration of network resources to support and secure that application as it is running.

"Performance and scale are basically table stakes," explained Dave Malik, senior director of solutions architecture at Cisco. Malik is one of the experts in the financial services market that doesn't just help Cisco sell products, but craft them. Performance and scale are not just table stakes for switching, but also for compute and for systems and application software. "But more importantly, it has to scale at a co-location facility or and enterprise datacenter or a service provider, and your automation becomes key. We are seeing more and more customers looking at multitenancy requirements, and the word of the day is microsegmentation – how do you segment the infrastructure from end to end so you can run your risk analytics next to your Hadoop infrastructure?"
One of the things that Cisco is doing with ACI is exposing APIs about the network fabric so the network can feed into various system, storage, and network management tools and have the network respond to changes in the application. "The days of configuring devices, configuring outputs, configuring port counters – those days are done," said Malik. "With ACI, you configure the intent of the application and how it will connect with other endpoints, what kind of compute and storage and security resources you want for it, and the entire fabric configures itself, from end to end. And when you talk to compliance or risk auditors, that becomes a central place to look at the system as a cohesive whole."

The idea with ACI sounds simple enough: You define from the app all the way down to the metal, and you start speaking in the language of applications, not access control lists and other network gorp. And you get away from the "spray and pray" method of overprovisioning networks to deal with peaks and congestion. You have deep application telemetry and visibility and can identify anywhere in the fabric where packets are lost and correct the issue.
Just as performance and scale are table stakes for the network and raw compute and storage, performance and scale are also table stakes for analytic tools like Hadoop. Will Ochandarena, director of product management at MapR Technologies, one of the key distributors of Hadoop, did a brief walk through the evolution of Hadoop from a slow batch system to an online one that is suitable for many applications in the financial services sector.
"In the beginning of Hadoop, there was just MapReduce, which is a very powerful used for a lot of things in financial services such as backtesting your algorithms or looking at risk models," said Ochandarena. "But MapReduce was slow." And, it was relatively tough to program, too. Even after you added SQL querying capability to MapReduce through the Hive database layer, it was still running on MapReduce and was still slow. But in the past two years or so, Hadoop has come a long way, as this chart from Ochandarena shows:
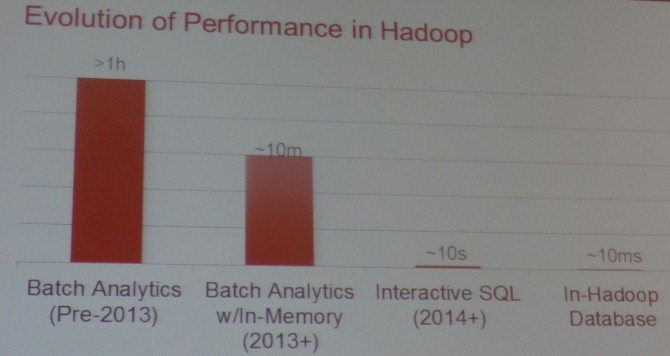
With the addition of in-memory features such as Apache Spark, the batch analytics that might take an hour or more could be done in maybe ten minutes. With the addition of interactive SQL on top of Hadoop, with projects like Apache Drill, then the same queries that used to take hours now take on the order of ten seconds. But now, with in-Hadoop databases such as MapR's own MapR-DB, which is a NoSQL data store that is compatible with the Apache HBase APIs. "We are seeing a latency of 10 milliseconds for gets and puts, and it can actually be used as an operational data store instead of just for analytics," said Ochandarena. "And that is important because it eliminates any data movement."
And just two weeks ago, the Hadoop provider demonstrated a time-series database layer called OpenTSDB running on top of MapR-DB that could ingest data at a rate of 100 million data points per second. Along with Spark Streaming and Storm, two other streaming data layers for Hadoop, the time series functions mean that financial services firms can contemplate a set of shared infrastructure that can run operational, analytics, and transactional systems on the same shared infrastructure – particularly if those assets are containerized on LXC or Docker. (A prospect that was not discussed, but which is part of the picture given that hypervisors provide much too heavy server virtualization than is perhaps required.)
Here is how these tools come together, as these partners see it, in the operational side of a financial services firm, and indeed, this also applies to any enterprise with complex infrastructure with performance, scale, and low latency as the basic tenets of its hardware and software:
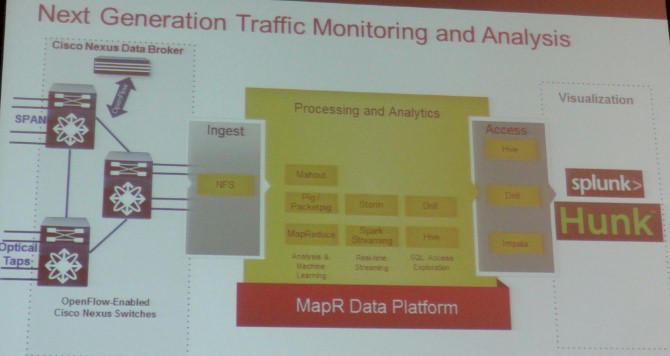
The idea is to use the telemetry coming out of the network and applications and pull it into Hadoop to store it permanently. You use the streaming features of Hadoop, such as Spark Streaming or Storm, to do real-time processing on events in the network and use machine learning to help feed information back into the infrastructure to control it. Drill, Hive, Impala and other tools are used to carve out subsets of this operational data using SQL commands, and then this data is pumped into a tool such as Splunk's Hunk to explore and visualize the datasets.






