



Unravelling Hadoop Performance Mysteries
Despite the fact that it runs on plain vanilla X86 servers and 64-bit operating systems, Hadoop is a complex beast that's prone to bottlenecks and performance issues. Getting Hadoop to run well isn't easy and typically requires a lot of tuning on the part of the customer or its system integrator. There's a good reason why the majority of the revenue recorded by Cloudera and Hortonworks are for technical services.
Now a group of researchers at Microsoft and the Barcelona Supercomputing Centre are working to create an online tool that will provide a standard way to predict Hadoop cluster performance in a reliable way. With Project Aloja, Microsoft and BCS hope to boil down all the variables that go into Hadoop performance and distill out which configuration changes have the biggest impact on performance and ultimately the cost born to the customer.
The first phase of the $1.2 million project, which was unveiled in July, involves creating a benchmarking platform, called Aloja, upon which researches can see how various Hadoop configurations impact the performance of jobs. The second stage will involve building a performance model based on all the data collected from the benchmark tests. For the final phase, researchers will use that model to create an automated way to determine the cost-effectiveness of a Hadoop workload across several configuration options.
There are more than 80 tunable parameters that impact Hadoop performance, according to the Project Aloja team, which is led by Rob Reinauer of Microsoft in Redmond, Washington and David Carrera of BSC in Spain. These variables range from hardware characteristics like storage type and network speed, to software characteristic, such as the number of mappers and reducers, HDFS block size, and size of virtual machines.
"Different hardware components impact per node performance in a variety of ways which also differ in their impact by workload type," write the researchers in their October paper ALOJA: a Systematic Study of Hadoop Deployment Variables to Enable Automated Characterization of Cost-Effectiveness. "Numerous software parameters exposed by both Hadoop and the Java runtime can have pronounced impacts and the different deployment patterns of on premise servers vs cloud based deployments add yet another layer of complexity."
For the first phase, Aloja was set up in two main configurations. The High-End Cluster uses Apache Hadoop and was based on server nodes equipped with dual six-core Intel “Sandy Bridge” processors and 64 GB of RAM. The researchers varied things up a bit with the storage and networking configurations, choosing SSDs or SATA drives and FDR InfiniBand or Gigabit Ethernet ports. A second cluster, called the Cloud IaaS Cluster, was designed to mimic a typical hosted Hadoop setup, and was run on Microsoft Azure A7 instances with a single eight-core processor.
To figure out which configuration variables are the most reliable predictors of performance, the researchers ran more than 5,000 Hadoop jobs using the HiBench benchmark. HiBench was released by Intel in 2012 and includes several micro-benchmarks, such as wordcount, sort, terasort, pagerank, Bayes machine learning, Mahout's K-means algorithm, DFSIOE_read and DFSIOE_write. The researchers tested a variety of Hadoop configurations and measured the relative performance of each job against the different hardware and software configurations. The researchers used a variety of tracing tools and techniques to tease out exactly what's happening in the various software layers, including the operating system, JVM, HDFS, MapReduce, and the application.

Researchers measured the effect of the number of mappers against the Hadoop HiBench benchmark
Researchers measured the impact of software configurations during the first phase. To do this, they varied the number of mappers configured in the Hadoop cluster hosted on Azure, and then measured how fast the Hi-Bench micro-benchmarks completed. According to their October paper," here's what they found:
"While pagerank, sort, and wordcount achieve best performance with 8 mappers (1 mapper per core), terasort achieves a 1.7x speedup when set to 6 mappers, mainly due to increased CPU I/O wait time caused by the concurrency while reading data. It can also be seen that a setting of 4 and 10 mappers yield sub-optimal performance. The default Hadoop configuration sets only 2 mappers," the researchers write.
The researchers also measured how various compression algorithms impact performance. According to the researchers, the ZLIB algorithm speeds up both the sort and wordcount micro-benchmarks, but not terasort. BZIP2, a high compression algorithm, meanwhile speeds up both sort and terasort but not wordcount. The snappy compression algorithm showed similar results to BZIP2. "For this experiment, the recommendation for sort and terasort will be to use BZIP2 compression, as it features better compression ratio, making data smaller, while achieving comparable or faster speedups to snappy," the researcher said.
On the hardware front, the researchers focused on two main areas with the first phase of the project, including the impact that solid state drives (SSDs) have and the difference that InfiniBand makes over plain Gigabit Ethernet. As you might expect, depending on the Hadoop workload, adding SSDs and/or InfiniBand can have a measured impact on performance.
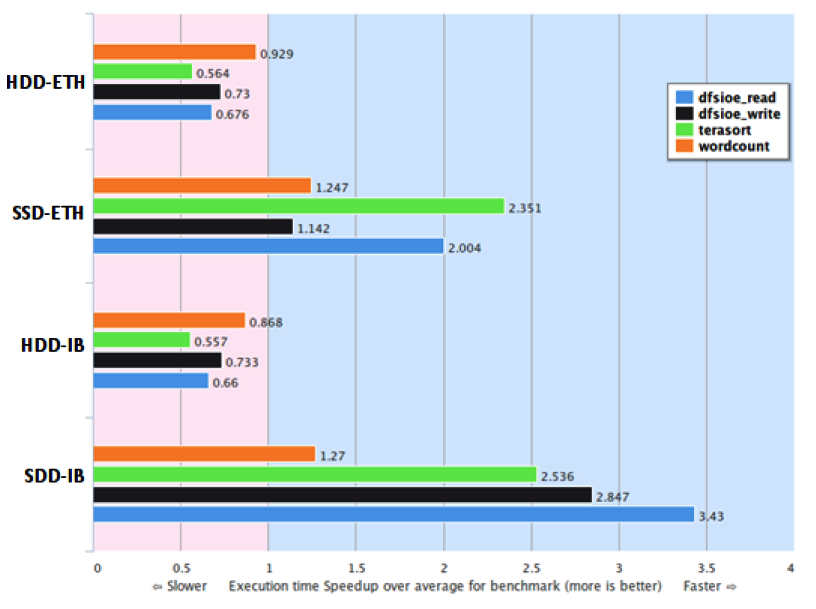
Researchers measured the effect that solid state drives and InfiniBand have on Hadoop performance.
The researchers found that just upgrading to SSDs while keeping the Gigabit Ethernet network can improve the performance of the terasort and DFSIOE_read micro-benchmarks by at least 2x. However, this setup had a negligible impact on the wordcount and DFSIOE_write micro-benchmarks. Just adding InfiniBand while keeping traditional spinning SATA disk had no significant impact at all. However, the combination of InfiniBand and SSDs had the greatest impact, particularly on the DFSIOE read and write micro-benches.
"These early findings show that in order to benefit from InfiniBand networks on the default Hadoop distribution, it requires a faster I/O subsystem i.e., SSD drives," the researchers wrote. "By using SSDs only, some benchmarks can speed up their execution up to 2x, while if combined with InfiniBand networks up to 3.5x."
The impact of various Hadoop storage configurations in the cloud was also measured. The test used the terasort micro-benchmark, and found that having two remote Hadoop storage volumes while keeping the Hadoop temp directory local was the ideal configuration.
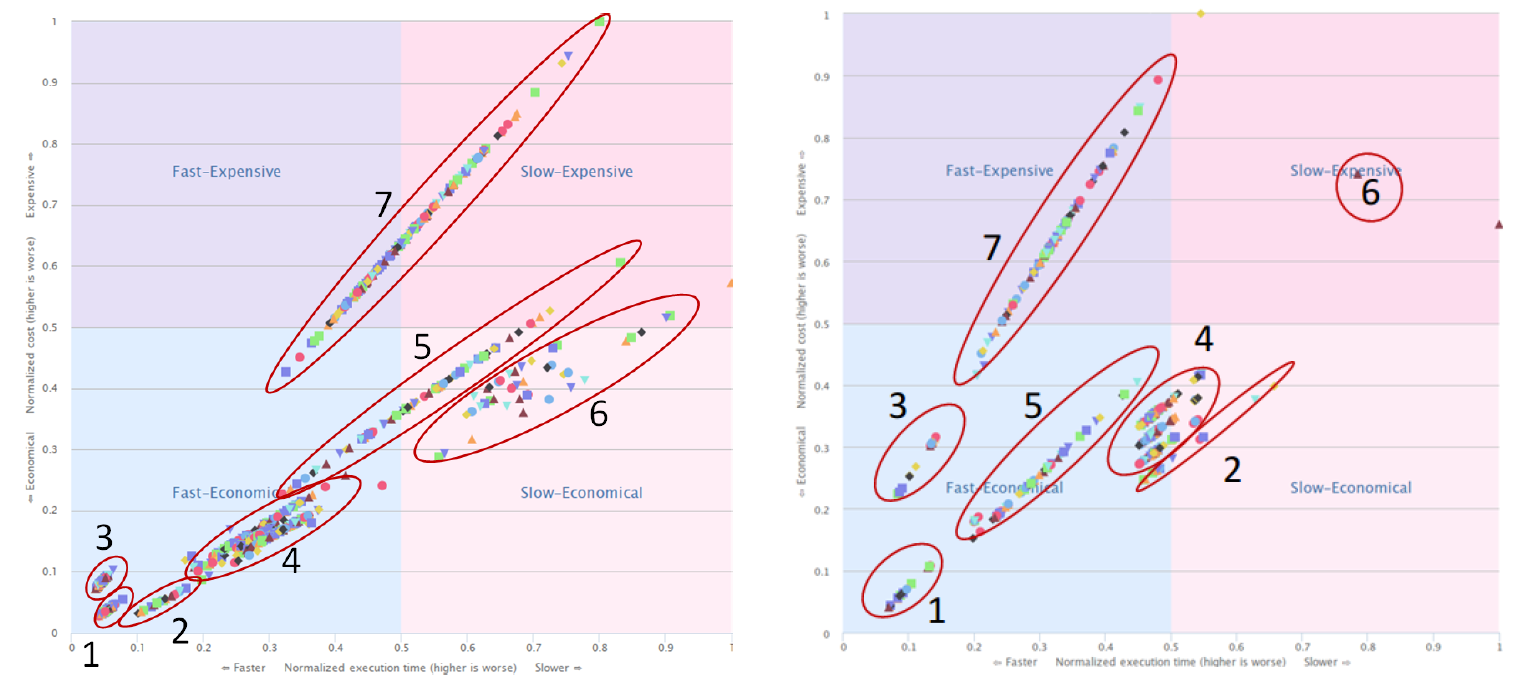
Cluster 1, which uses SSDs on GbE, showed the best price/performance for both the terasort and wordcount benchmarks.
Finally, the researchers brought cost into the equation, and measured how seven different configuration types perform on different benchmarks. An on-premise cluster comprised of SSD disks and Gigabit Ethernet scored the best price-performance against both the wordcount and terasort benchmarks. The Azure instance equipped with SSDs, Gigabit Ethernet, and a local copy of the temp directory also scored well in the terasort test (which is I/O intensive), but scored more poorly in the wordcount test (which is CPU intensive).
Interestingly, the data shows that the particular software configuration changes that are made for clusters based on spinning SATA drives--as measured by the wide price-performance range of clusters 5 and 7 in the above graphic--can have a big impact on performance and cost. In other words, there is a lot more tuning required to eke out the most performance of your Hadoop cluster if you're using spinning SATA drives compared to SSDs.
Project Aloja continues, and the researchers aim to make their data available to the public through the Aloja Web tool, which will allow them to see which of the 80 tunable parameters impact performance. "Our intent is that researchers and organizations evaluating or deploying the Hadoop solution stack will benefit from this growing database of performance results and configuration guidance," the researchers write.
Also, the researchers will also go beyond Apache Hadoop running on Linux. "We started with open source, Apache on Linux, but we are in the process of expanding our investigations to windows and commercial PAAS Hadoop services," Microsoft's Reinauer tells EnterpriseTech.
Related Items:
Hadoop Finds Its Place In The Enterprise
Cluster Sizes Reveal Hadoop Maturity Curve
Why Hadoop Is The New Backbone Of American Express






