



NVIDIA Cries Foul on Intel Phi AI Benchmarks

This week saw the eruption of a vendor spat when NVIDIA, developer of GPUs widely used in the AI/machine learning market, alleged foul play against Intel in recent comparative benchmark results involving Intel’s Xeon Phi processors. While NVIDIA makes some fair points about the methodology employed by its rival, Intel announced impressive news of its own on the AI/Xeon Phi front.
First, let’s look at NVIDIA’s criticism of Intel that came in the form of a blog post by Ian Buck, vice president of accelerated computing, who declared that Intel compared Xeon Phi to out-of-date NVIDIA benchmarking data. Specifically, Buck was responding to a slide used by Intel at the ISC conference in Germany two months ago:
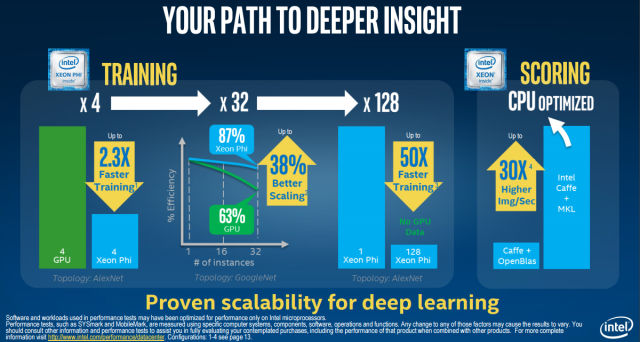 “Intel used Caffe AlexNet (benchmarking) data that is 18 months old, comparing a system with four (NVIDIA) Maxwell GPUs to four Xeon Phi servers,” Buck wrote. “With the more recent implementation of Caffe AlexNet, publicly available here, Intel would have discovered that the same system with four Maxwell GPUs delivers 30 percent faster training time than four Xeon Phi servers. In fact, a system with four Pascal-based NVIDIA TITAN X GPUs trains 90 percent faster and a single NVIDIA DGX-1 is over 5x faster than four Xeon Phi servers.”
“Intel used Caffe AlexNet (benchmarking) data that is 18 months old, comparing a system with four (NVIDIA) Maxwell GPUs to four Xeon Phi servers,” Buck wrote. “With the more recent implementation of Caffe AlexNet, publicly available here, Intel would have discovered that the same system with four Maxwell GPUs delivers 30 percent faster training time than four Xeon Phi servers. In fact, a system with four Pascal-based NVIDIA TITAN X GPUs trains 90 percent faster and a single NVIDIA DGX-1 is over 5x faster than four Xeon Phi servers.”
In response to Intel’s statement that Xeon Phi offers 38 percent better scaling than GPUs across nodes, Buck said, “Intel is comparing Caffe GoogleNet training performance on 32 Xeon Phi servers to 32 servers from Oak Ridge National Laboratory’s Titan supercomputer. Titan uses four-year-old GPUs ([NVIDIA] Tesla K20X) and an interconnect technology inherited from the prior Jaguar supercomputer. Xeon Phi results were based on recent interconnect technology.”
Perhaps in an attempt at graciousness, Buck allowed that “Few fields are moving faster right now than deep learning. Today’s neural networks are 6x deeper and more powerful than just a few years ago. There are new techniques in multi-GPU scaling that offer even faster training performance. In addition, our architecture and software have improved neural network training time by over 10x in a year by moving from Kepler to Maxwell to today’s latest Pascal-based systems, like the DGX-1 with eight Tesla P100 GPUs.”
He then added, somewhat snarkily, “So it’s understandable that newcomers to the field may not be aware of all the developments that have been taking place in both hardware and software.”
Intel, for its part, declined to engage in a detailed rebuttal, issuing a statement to EnterpriseTech from “an Intel spokesperson”: “It is completely understandable that NVIDIA is concerned about us in this space. We routinely publish performance claims based on publicly available solutions at the time, and we stand by our data.”
NVIDIA currently has about 75 percent of the market for GPUs, which are the processors of choice for the deep learning community – enthusiasts and researchers alike. But Intel remains aggressive in this market, and in fact at the Intel Developer Forum in San Francisco this week teased a new Phi product, codenamed “Knights Mill,” aimed at machine learning workloads.
As reported in HPCwire, Intel brought out customers at IDF to talk up machine learning on Phis, one of them being Chinese internet giant Baidu (also an NVIDIA customer), which provided a hefty endorsement. The company, which has relied heavily on NVIDIA GPUs to run its deep learning models, announced that it will be using Xeon Phi chips to train and run Deep Speech, its speech recognition service.
Baidu also announced a new HPC cloud service, featuring Xeon Phis. “The Xeon Phi-based public cloud solutions will help bring HPC to a much broader audience,” said Wang. “We think it will mean not only lower cost but greater velocity of HPC and AI innovations.”






