



Where Do We Come From? Ancestry.com’s 19B-Record ‘Big Tree’ Database May Have the Answer

("Where Do We Come From? What Are We? Where Are We Going?" Paul Gauguin Source: Museum of Fine Arts, Boston)
“Where Do We Come From? What Are We?” Not only Paul Gauguin (see picture) but most of humanity has been vexed by these questions since… well, since the dawn of humanity. “If the means were available,” observed science fiction writer Clifford Simak, “we could trace our ancestry – yours and mine – back to the first blob of life-like material that came into being on the planet.” Most of us aren’t interested in going back that far on the family tree. A few hundred years will usually suffice.
For this there’s genealogy companies like 23andMe and Ancestry.com, a $680 million firm that combines historical research, data analytics, machine learning and DNA samples (taken from customers’ saliva) to reveal your ethnic heritage and connect you to relatives, living and dead, obscure and famous. While genealogy has been around at least since kings sought proof of legitimacy - proof more convincing than, say, pulling a sword from a stone - the DNA saliva test is a relatively new addition to genealogical science that has become a cultural phenomenon, a good conversation starter and, speaking from personal experience, a confirmer or debunker of family lore (I didn’t know I’m 0.02 percent Italian heritage until 23andMe told me so). It’s fun.
It’s also a gigantic Big Data challenge. Ancestry.com has 19 billion digitized historical records, 80 million family trees, 8 billion person profiles, a genomics network of 2.5 million DNA samples (which test for 700 genetic markers), and 175 million sharable family photos, documents and written stories. In all, there are 10PB of data in the Ancestry.com database, a jumble of structured and unstructured data from many sources – some dating back hundreds of years – that receives an average of 400 data changes per minute and is growing by 2 to 3 million records per month.
Since Ancestry.com’s mission is to help people understand how they connect to the rest of the world, all their variegated data must be connected within its “Big Tree” database so that vital family information, formerly scattered around the world, are now centrally and digitally stored to quickly connect the vital tissue of family backgrounds. How the company does this was the topic of a presentation at SC16 last month in Salt Lake City by two Ancestry.com data scientists.
But digitization and genomics, while taking genealogy far, doesn’t solve every problem. Building a family tree mixes data science and human judgment because the quality of historical family data varies. Family trees in the proverbial family Bible, newspaper obituaries and court records can be incomplete and faulty, the more so the further one goes back into the mists of time.

Ancestry.com's Tyler Folkman
“Having more than 10PB of data, and of many different kinds (of data), makes it a very interesting problem,” said Tyler Folkman, an Ancestry.com data scientist. “Our data is very unclean. We have NLP (natural language programming) problems from our documents; we have computer vision problems for how to read those documents. We have traditional machine learning problems for how to predict things. It’s quite interesting.”
“Entity Resolution” is the core challenge for Ancestry.com, the positive identification of individuals in family trees. It is not, in the end, an exact science with plenty of inference involved. When there are doubts about the identities of two individuals who may, or may not be, the same person, Ancestry.com generates ranking recommendations according to degree of certainty: S for strong degree of certainty they are the same person; C for confident they’re the same; PS for probably the same; PD for probably different; D for different; CD for cannot decide. As exercises in Entity Resolution devolve down this ranking scale, big data leaves off and professional genealogists on the Ancestry.com staff take over.
Naturally, the company tries to solve as many Entity Resolution problems as possible without human intervention. To do this, it continually pours more (and updated) data into its data warehouse while refining the algorithms in its Big Tree analytics infrastructure.
“At heart we’re a data company,” said Atanu Roy, an Ancestry.com senior data scientist. “We have 19 billion records and if you do not do modern machine learning then you can’t make sense of it."
He said Ancestry.com’s compute infrastructure is CPU-only, though he expects the company will eventually introduce GPUs into the mix.
“We use highly parallel machine learning,” Folkman said. “It’s a fun problem because a lot of machine learning happens in batch, but we run ours highly parallel. So we scale out to a lot of nodes because we get around 400 changes per minute through Ancestry.com. We get a lot of changes we want to update for our users as fast as possible, which means we run through the Entity Resolution process a lot. So we scale up to super high parallel on a lot of beefy machines.”
To handle Entity Resolution at scale, Ancestry.com has developed Thunder Compare, its machine learning algorithm that conducts “compares” of individuals to establish their identities. Thunder Compare is trained to recognize “features” in individual records – features being key identifying elements, such as last name, birthday, names of parents, place of birth, and so forth.
Take how Thunder Compare is trained to use names.
“You might expect a really good feature is your name,” Roy said. “But you can’t just take two peoples’ names, compare them and assume they’re the same person because we know people make typos, we need to account for that. We know there are synonyms for names, such as Charlie and Charles, we have to account for that. We have to account for name uniqueness. If there are two John Smiths that match, am I confident in that? As opposed to Xavier – if two Xaviers match, that says a lot. Two John Smiths, not so much.”
To demonstrate how devilishly demanding Entity Resolution can be on Thunder Compare, Folkman cited the case of two records for women named Rebecca Horton born in the 1700s in Westchester County, New York. Both records listed the same parents, both showed the parents to be from Rye, NY; and both records shared the same long list of Horton siblings. But one record showed Rebecca to have been born in 1713, the other record showed the birth year as 1734 along with a birth place of White Plains, NY. Are these two records of the same person? Or did a careless clerk enter the wrong birth year in one of the records (possibly with the evil intent of confounding future genealogists)?
Ticking down the list of shared features it would be easy to conclude the two Rebeccas are the same. But proof that they are very likely different is found in the record of the Rebecca born in 1713; looking down her list of siblings, one sees another Rebecca born in 1734. Rebeccas’ parents gave two of their daughters the same name, a not uncommon practice in large families of the 18th century.
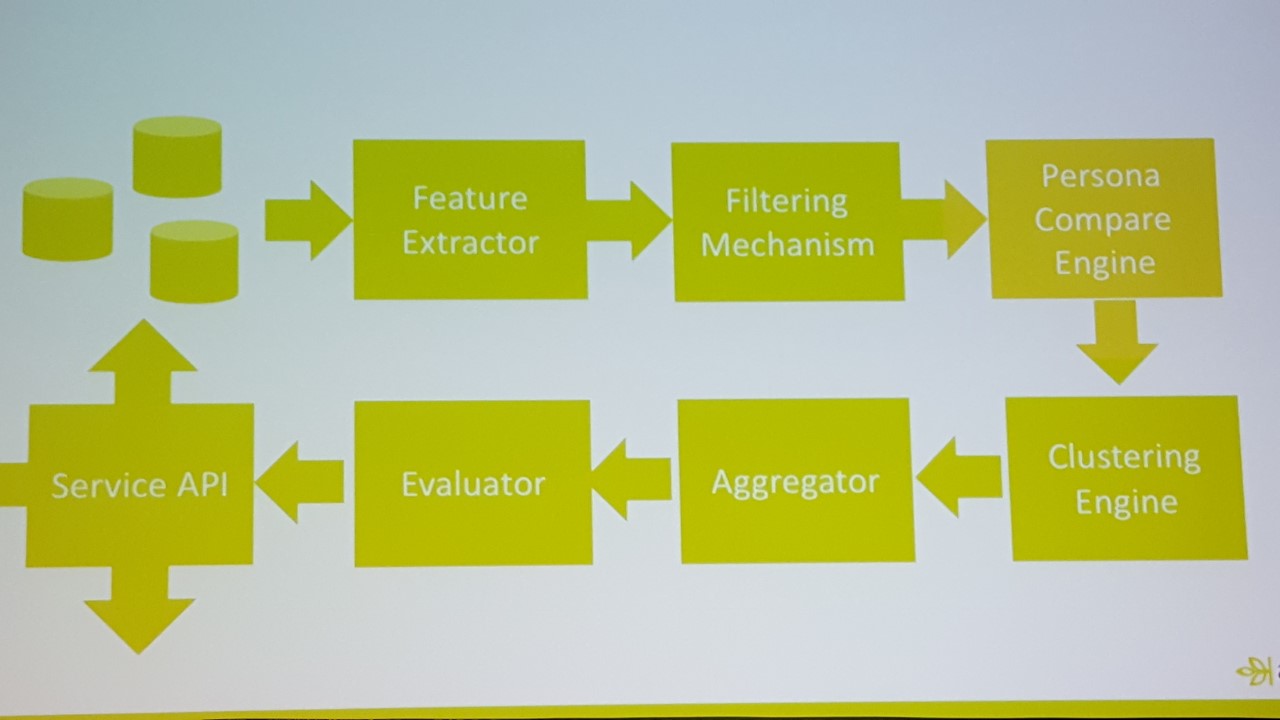
Ancestry.com's Big Tree framework
Once entities have been resolved, Ancestry.com does what’s called an “N2 comparison,” which places individuals within the mother of all family trees, called the “Big Tree,” that includes everyone in the Ancestry.com’s database. The N2 comparison capability is trained to limit the scale of compares by eliminating unlikely family relationships – for example, if two children were born in the same year but on different continents it can be assumed they’re not siblings – to minimize wasted compute cycles and to complete N2 workloads in reasonable timeframes.
“Remember, we have 18 or 19 billion records,” Roy said. “The number of comparisons is10 to the power of 20. Even with the most powerful supercomputer it would take decades if not centuries to do all the comparisons. We have billions of things we’re comparing, so we have to be fast.”






