



Drug Developers Enlist Google Cloud HPC in the Fight Against ALS
(Source: Cycle Computing)
Within the haystack of a lethal disease such as ALS (amyotrophic lateral sclerosis / Lou Gehrig's Disease) there exists, somewhere, the molecular needle that will pierce this therapy-resistant affliction. Finding it is a trial-and-error process of monumental proportions for scientists at pharmaceuticals, medical research centers and academic institutions. As models grow in scale so too does the need for HPC resources to run simulations iteratively, to try-and-fail fast until success is found.
That’s all well and good if there’s ready access to HPC on premises. If not, drug developers, such as ALS researcher Dr. May Khanna, Pharmacology Department assistant professor at the University of Arizona, have turned to HPC resources on public cloud services. But using AWS, Azure or Google introduces a host of daunting compute management problems that tax the skills and time availability of most on-site IT staffs.
These tasks include data placement, instance provisioning, job scheduling, configuring software and networks, cluster startup and tear-down, cloud provider setup, cost management and instance health checking. To handle these cloud orchestration functions tied to 5000 cores of Google Cloud Preemptive VMs (PVMs), Dr. Khanna and her team at Arizona turned to Cycle Computing to run “molecular docking” simulations at scale executed by Schrödinger Glide molecular modeling drug design software.
The results: simulations that would otherwise take months have been compressed to a few hours, short enough to be run during one of Dr. Khanna’s seminars and the output shared with students.

Dr. May Khanna
Developing new drugs to target a specific disease often starts with the building blocks of the compounds that become the drugs. In the case of ALS, it is suspected that the disease begins when two proteins ("targets" is the term Dr. Khanna used) combine and then interact in a malignant way. Dr. Khanna and her team are seeking molecules that can targets specific proteins and break them apart, preventing their fatal interaction. This research is conducted by simulating how the small molecules "dock" to specific locations on the protein. These simulations are computationally intensive, and many molecules need to be simulated to find a few good docking candidates.
Obviously, the bigger the sample the more likely researchers are to find molecules that dock to the proteins. Without powerful compute resources, researchers must artificially constrain their searches, limiting the number of molecules to simulate. And they only restrict their docking simulation to an area of the protein known to be biologically active. Even with these constraints, running simulations takes a long time. Done right, molecular docking is done quickly and interactively; shortening the iteration time is important to advancing the research.
The objective of Dr. Khanna’s work was to simulate the docking of 1 million compounds (molecules) to one target protein. After a simulation was complete, the protein was produced in the lab, and compounds were then tested with nuclear magnetic resonance spectroscopy.
“It’s a target (protein) that’s been implicated in ALS,” the energetic Dr. Khanna told EnterpriseTech. “The idea is that the particular protein was very interesting, people who modulated it in different ways found some significant improvement in the ALS models they have with (lab) mice. The closer we can link biology to what we’re seeing as a target, the better chance of actually getting to a real therapeutic.”
“Modulating,” Dr. Khanna explained, is disrupting two proteins interacting in a way that is associated with ALS, a disease that currently afflicts about 20,000 Americans and for which there is no cure. “We’re trying to disrupt them, to release them to do their normal jobs,” she said.
She said CycleCloud plays a central role in running Schrödinger Glide simulations. Without Google Cloud PVMs, simulations would take too long and model sizes would be too small to generate meaningful results. Without CycleCloud, the management of 5,000 PVM nodes would not be possible.
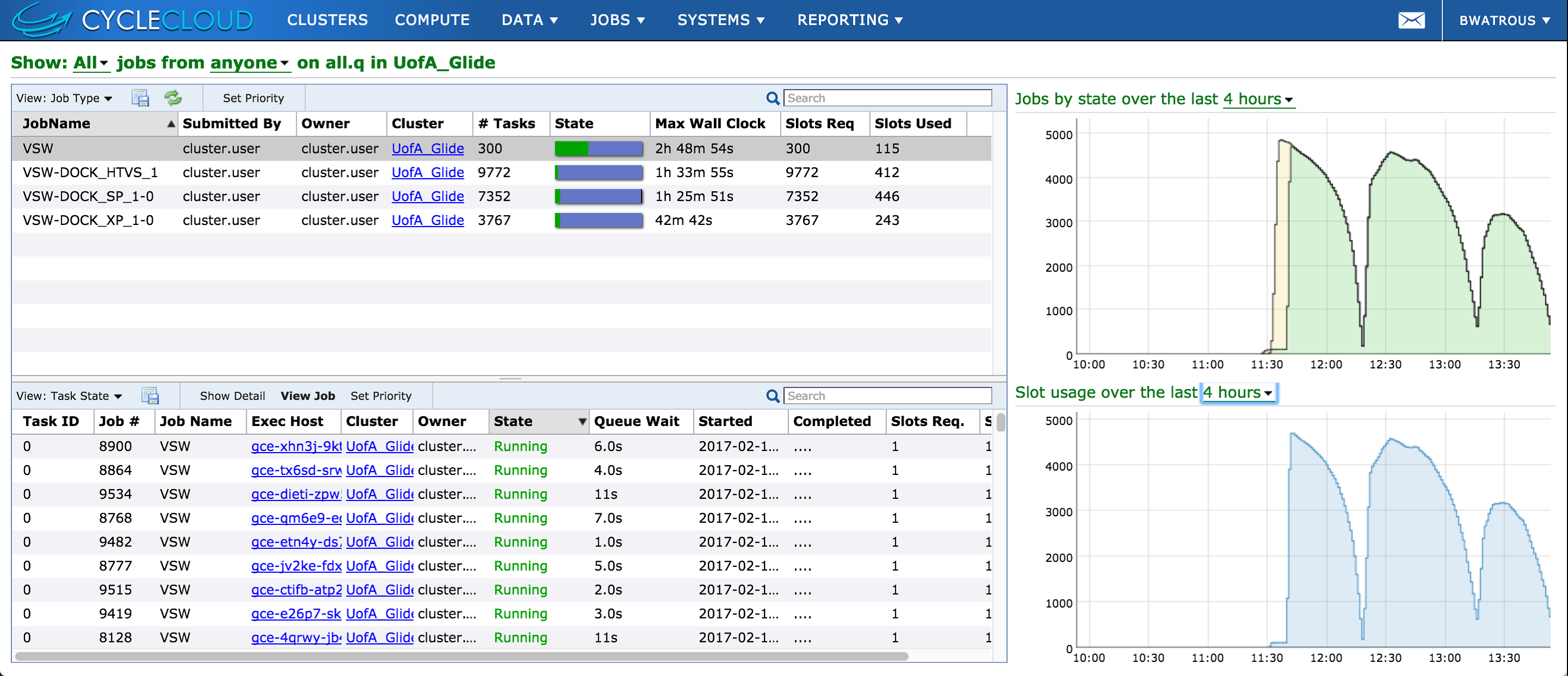 CycleCloud provides a web-based GUI, a command line interface and APIs to define cloud-based clusters. It auto-scales clusters by instance types, maximum cluster size and costing parameters, deploying systems of of up to 156,000 cores while validating each piece of the infrastructure. Additionally, it syncs in-house data repositories with cloud locations in a policy / job driven fashion, to lower costs.
CycleCloud provides a web-based GUI, a command line interface and APIs to define cloud-based clusters. It auto-scales clusters by instance types, maximum cluster size and costing parameters, deploying systems of of up to 156,000 cores while validating each piece of the infrastructure. Additionally, it syncs in-house data repositories with cloud locations in a policy / job driven fashion, to lower costs.
It should be noted that the use of Google Cloud’s PVMs, while helping hold down the cost of running simulations to $200, contribute an additional degree of complexity to Dr. Khanna’s project work. Preemptible compute capacity offers the advantage of a consistent price not subject to dynamic demand pricing, as are other public cloud instances. PVMs are assigned to a job for a finite period of time but – here’s the rub – they can be revoked at any moment. While Dr. Khanna’s workflow was ideal for leveraging PVMs, since it consists of small, short-running jobs, PVMs can disappear without warning.
In the case of Dr. Khanna’s ALS research work, said Jason Stowe, Cycle Computing CEO, “if you’re willing to getting rid of the node, but you’re able to use it during that timeframe at substantially lower cost, that allows you get a lot more computing bang for your buck. CycleCloud automates the process, taking care of nodes that go away, making sure the environment isn’t corrupted, and other technical aspects that we take care of so the user doesn’t have to.”
The simulation process is divided into two parts. The first step uses the Schrödinger LigPrep package, which converts 2D structures to the 3D format used in the next stage. This stage started with 4 GB of input data staged to an NFS filer. The output data was approximately 800KB and was stored on the NFS filer as well. To get the simulation done as efficiently as possible, the workload was split into 300 smaller jobs to assist in scaling the next stage of the workflow. In total, the first stage consumed 1500 core-hours of computation.
The Schrödinger Glide software package performs the second stage of the process, where the actual docking simulation is performed. Each of the 300 sub-jobs consists of four stages, each with an attendant prep stage. The total consumption was approximately 20,000 core-hours using 5,000 cores of n1-highcpu-16 instances. Each instance had 16 virtual cores with 60 gigabytes of RAM. The CycleCloud software dynamically sized the cluster based on the number of jobs in queue and replaced preempted instances.
Dr. Khanna’s research is the early stages of a process that, if successful, could take several years before reaching human clinical trials.
“The faster we can do this, the less time we have to wait for results, so we can go back and test it again and try to figure out what compounds are really binding,” she said, “the faster the process can move along.”
Dr. Khanna said plans are in place to increase the size of the pool of potential compounds, as well as include other proteins in the simulation to look for interactions that would not typically be seen until later in the process. The team will also simulate over the entire surface of the protein instead of just a known-active area unlocking “an amazing amount of power” in the search process, she said.
“That jump between docking to binding to biological testing takes a really long time, but I think we can move forward on that with this cloud computing capacity,” she said. “The mice data that we saw was really exciting…, you could see true significant changes with the mice. I can’t tell you we’ve discovered the greatest thing for ALS, but showing that if we take these small molecules and we can see improvement, even that is so significant.”






