



‘Run Anywhere’ Enterprise Analytics and HPC Converge at TACC

The Stampede supercomputer at TACC
Advances in storage, processor, and cloud technology have made run-anywhere big data analytics available to small and medium sized businesses (SMBs) as well as Fortune 1000 companies.
Run-anywhere means that only a processor and sufficient memory and storage to support a given data analytics task need be provided – and that all the historical data businesses have been collecting can now be analyzed by state-of-the-art machine-learning algorithms to gain better market insight, increase efficiency, and most importantly, increase the ROI of data-derived investments.
For enterprise applications, it is this last step, the application of machine learning (inferencing) that delivers the ROI for business analytics. However to get there, the data must be extracted (generally from unstructured data sources) and preprocessed into a representative training set so the model used for inferencing can be trained to solve the problem of interest.
If you are drowning in data, then the preprocessing of the data is likely to be as big and important a problem as the training process that creates the value-add model used for inferencing. This is why storage, as well as compute, is so important for data analytics.
The Drowning-in-Data Challenge
Most businesses are drowning in data, but few like to admit it, nor – for competitive reasons – do they like to talk about how they’re addressing the problem with data analytics.
To get a view into new analytics strategies, we look to relevant open data analytics research that is being performed at organizations such as the Texas Advanced Computing Center (TACC) at The University of Texas at Austin, noting that the software tools and techniques used there can be applied by enterprise users.
![]() Generally speaking, TACC data analytics techniques discussed here are CPU-based, which means they can run anywhere, there is no need for an accelerator. The key point is that project scale – i.e., the amount of data and desired time-to-solution – dictates whether enterprises should either purchase individual workstations and small computational clusters or, alternatively, use on-demand cloud instances to perform data analytics using their own data. This also means that the memory and storage capabilities of the hardware need to be able to handle to the data-analytics task.
Generally speaking, TACC data analytics techniques discussed here are CPU-based, which means they can run anywhere, there is no need for an accelerator. The key point is that project scale – i.e., the amount of data and desired time-to-solution – dictates whether enterprises should either purchase individual workstations and small computational clusters or, alternatively, use on-demand cloud instances to perform data analytics using their own data. This also means that the memory and storage capabilities of the hardware need to be able to handle to the data-analytics task.
To help enterprise (and scientific) users, TACC provides access to several Dell PowerEdge systems that incorporate updated Intel Xeon and Xeon Phi processors, along with Intel Omni-Path Architecture interconnect in the case of TACC’s newest system, called Stampede2,.
TAAC’s big data analytics capabilities have been shown to perform web analysis using 10**18 datum (on the order of an exabyte, or million trillion bytes of data) while running machine learning applications that can take on big jobs, such as reverse engineer cellular networks. They also can create and analyze distributed computational approaches that provide a superlinear speedup, making big data analytics possible using distributed computers.
According to Bill Barth, TACC Director of High Performance Computing, “TACC has deployed a series of data-intensive computing resources that researchers can use to run almost all workloads written in many languages while also exploiting large memory.”
The TACC machines mentioned in this article blur the lines between cloud, storage, and HPC clusters, providing CPU-based compute nodes on Wrangler, Stampede1 (which featured Intel Xeon and first-generation Xeon Phis) and Stampede2 (featuring both Intel Xeon Phi and Intel Xeon Scalable processors), coupled with large memory availability to speed data extraction and preprocessing, all of which combine to simplify data analytics applications, rather than introducing the complications of an accelerator and associated memory limitations. For these reasons, the TACC systems are known for providing a relative uncomplicated user environment.
The run-anywhere approach also means that software resulting from these projects can be used to advance the state-of-the-art for enterprise as well as scientific users. Think Netflix-scale recommendations of movies, or Facebook order-of-magnitude matching of friends, but in the enterprise space – with a run-anywhere software capability.
What we’re seeing, in short, is the convergence of HPC and enterprise data analytics. For example, to enable the wealth of its MPE data analytics applications to run in the cloud, Nelsen Corporation used the simple trick of having a Hadoop job write the machine file with the IP address of each Hadoop node on job startup. In this way, supercomputers such as the Dell EMC-built Stampede can contribute to enterprise-level analytics workloads. For more information see, “Nielsen and Intel Migrate HPC Efficiency and Data Analytics to Big Data”.
Exadata “Dark Web” Analytics in the Cloud
Conducting “dark web” analytics projects, Chris Mattmann, principle data scientist at the National Science Foundation and the Jet Propulsion Laboratory, uses the 600 TB of SSD storage within TACC’s Dell EMC Wrangler system to accelerate Hadoop-based data analytics. This has implications for enterprise users searching for identify theft in the dark web, or researching the latest security attacks and phishing schemes, along with law enforcement and national defense organizations fighting terrorism.
Mattmann collects millions of web pages that are then processed while looking for thousands of features in thousands of file types.
As part of the project, Mattmann is currently using Google TensorFlow-trained deep-learning neural networks for image recognition to classify large amounts of data he gathers using web crawlers on the dark web, which is not indexed for searching by standard web crawlers by Google or other public search providers. The collected image, video, and text information is then analyzed to provide actionable information.
This highlights TACC’s dual machine learning capabilities: Stampede provides a petascale-level training capability while Wrangler provides an exabyte-scale inferencing capability. In later projects, Mattmann envisions training deep-learning neural networks to create custom classifiers, but at the moment he and his team are currently using Wrangler as a big inferencing engine.
Being cloud-based, Mattmann has flexibility across public cloud service providers in where he can run workloads. Low latency storage is key to large data analytics projects, which is what makes Wrangler a preferred platform. Mattmann states that Wrangler allows them to “develop techniques that are helping save people, stop crime, and stop terrorism around the world.” Now developed, Mattmann said these techniques are available for others to use.
Mattmann also believes that advances in storage technology can accelerate big data analytics, including the potential for “fat nodes” with tens of terabytes in main memory. This would significantly improve data access latency, which is critical to unstructured data analytics, especially graph algorithms. In turn, many enterprise data analytic problems can be expressed in terms of a graph (i.e. who communicated with whom, what products were bought relative to other products), a more readily understand way of presenting analytics results for critical business insights.
The War on Cancer
Reflecting on the large data volumes found in cancer research (and representative of the data volumes found in the health and pharmaceutical communities), Dr. Michael Levin, professor of biology at Tufts University and director of the Allen Discovery Center at Tufts observes that “we, as a community are drowning in quantitative data coming from functional experiments.”
The good news, Levin said, is “that the machine learning platform got us to a capability to do something we couldn't do before, at the bench, in real living organisms." In this case, to create a tadpole with pigmentation that doesn’t exist in nature, a research effort with implications for treating melanoma.
Cancer is extremely difficult to understand because treatment is deeply intertwined with intricate cellular control networks throughout the organism. Advances in biomedical equipment means that ever larger amounts of data are being generated. This is good as it means scientists can find rare events, but as Michael Levin’s observes, "Extracting a deep understanding of what's going on in the system from the data in order to do something biomedically helpful is getting harder and harder."
For example, a research team from Tufts and the University of Maryland/Baltimore County had access to nearly a decade’s worth of individual laboratory experiments measuring how various drugs and proteins affected pigmentation cells in tadpoles. Some laboratory treatments would induce a melanoma-like outcome by interrupting the electrical communication with other cell types. Each experiment gave insight into only a portion of the cellular regulatory network.
Using TACC Stampede, the research team has constructed a representative cellular regulatory network and then, using machine-learning techniques, have effectively ‘evolved’ the differential equations specified at each node of the network to best reflect the results of the known laboratory experiments.
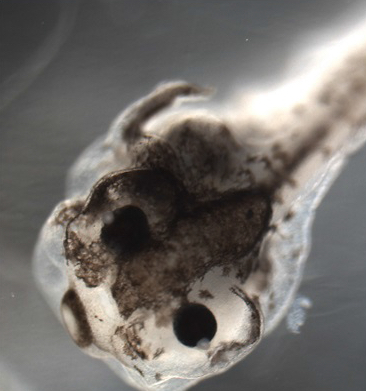
AI uncovered interventions needed to obtain never-seen-in-nature results. Pigment cells over a tadpole's left eye became cancer-like; those over the right eye remained normal. Credit: Patrick Collins, Tufts University
To test this reverse-engineered model, the team was able to uncover the exact interventions needed to obtain a specific, never-seen-in-nature pigmentation pattern in the tadpoles. Further, this model was accurate enough to also predict the percentage of the population of tadpoles with the mixed pigmentation. Levin says the model "was good enough to predict new outcomes to experiments that no one had done before."
AI uncovered interventions needed to obtain specific, never-seen-in-nature results. Pigment cells over a tadpole's left eye became cancer-like; those over the right eye remained normal. Credit: Patrick Collins, Tufts University
In short, TACC Stampede1 could adjust the representative cellular regulatory network to accurately represent nearly a decade’s worth of laboratory experiments. The resulting model could be used to determine the treatment required to induce a desired result in the tadpole. Perhaps similar analytics and modeling can, in the future, be used for people with melanoma.
The Allen Institute makes its software available for others noting, “While many aspects of our pipelines could benefit from special hardware, we strive to keep them generalizable and have not yet made any efforts to optimize for specific hardware setups.” Being CPU-based, this means the software should be able to run anywhere.
Big Data Nomadic Algorithms
Inderjit Dhillon (Gottesman Family Centennial Professor of Computer Science and Mathematics and Director of the ICES Center for Big Data Analytics at the University of Texas at Austin) is using TACC resources to address performance issues involved in utilizing bulk synchronization for distributed computing, which requires each processor to stop after computing a result and then wait for all computations within the “bulk” to be completed.
The Nomadic algorithm is designed to eliminate this delay by considering each parameter a “nomad” that asynchronously moves to another processor once the work is done. This delivers a superlinear speedup, which occurs in a parallel computer when the acceleration in time-to-solution is actually greater than the number of parallel processing elements used for the calculation. For example, Dhillon reported that the observed nomadic speedup was greater than a factor of 1000 when using 1000 Stampede processors.
On the basis of such results, the NSF provided a $1.2M grant to Dhillon’s group to further their Nomadic algorithm research.
TACC Resources
The Wrangler supercomputer combines a 10 petabyte storage system and a NAND flash global object store that services 120 CPU-based servers for data access and analytics. The system was designed to run a range of data workflows, including Hadoop and databases along with MPI and HPC workloads.
Stampede1 delivered more than 9 PF/s of Intel Xeon and Intel Xeon Phi floating-point performance. It has been replaced by the Stampede2 system, which utilize 4,200 Intel Xeon Phi 7250 second generation (Knights Landing) processors and includes Many Integrated Core (MIC) compute nodes that will communicate over an Intel Omni-Path Architecture network.
Rob Farber is a technology consultant and author.






