



Intelligent Interconnect Architecture: AI Enabler
Source: Mellanox
Data analytics has become an essential function within today’s high performance enterprise data centers, clouds and hyperscale platforms. AI and machine learning (ML) are pillars of today’s technological world, offering solutions for better and more accurate decisions based on great amount of data. Although the basic concept behind AI – neural networks creating rules that machines use to make smart decisions – is not new, until recently, it was difficult to implement.
Training a deep neural network requires complex computations. However, CPU and GPU technologies are not keeping up with the growing needs for deep neural network trainings. As an example, a GoogLeNet deep network training takes 21 days to train on an ImageNet-1K on a single GPU. Therefore, distributing the learning phase into a large cluster of CPUs / GPUs is essential as it can dramatically accelerate the learning time.
Multiple software implementations are now available, including reduction trees and other algorithms. All the existing implementations use data movement from one node to another to calculate the summation, and are limited performance-wise. Moving the summation operation into smart network elements dramatically improves the operation performance in several ways. It reduces the amount of data moving from one node to another, reduces the time to complete the sum operation, and fully offloads the operation from the CPU / GPU to the network, therefore allowing better utilization of the GPU resource.
Breakthrough in Network Technology
Industry-wide, it is recognized that the CPU has reached the limits of its scalability. Moving increasing amounts of data to an end-point – the CPU – before the data can be analyzed creates performance bottlenecks. The old CPU-centric architecture is being replaced by a data-centric architecture. We need to move computing to the data and execute data analytics everywhere. This calls for an intelligent network to act as a “co-processor,” sharing the responsibility for handling and accelerating data workloads. By placing the computation for data-related algorithms on an intelligent network, it is possible to dramatically improve both application performance and scalability.
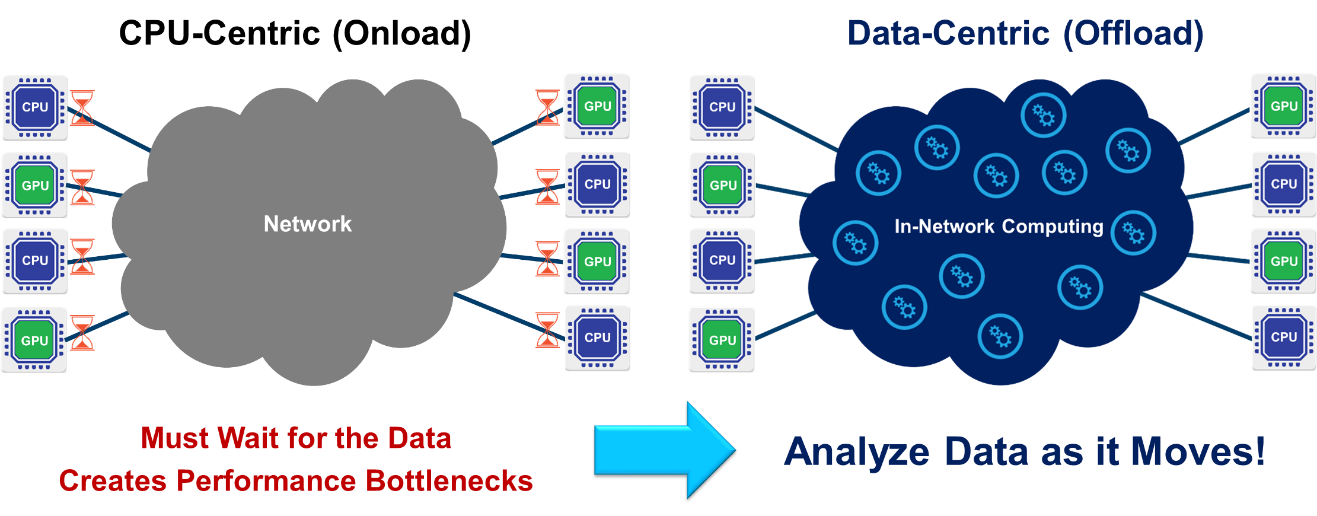 The new generation of smart interconnect solutions is based on a data-centric architecture, which can offload all network functions from the CPU to the network and perform computation in-transit, increasing the system’s efficiency. This new architecture enables the “smart” interconnect to support the management and execution of more data algorithms within the network. In effect, users can run algorithms on data as it’s transferred within the system interconnect rather than having to wait for data to reach the CPU. Smart interconnect solutions can now deliver both In-Network Computing and In-Network Memory, representing the industry’s most advanced approach to achieve performance and scalability for AI systems.
The new generation of smart interconnect solutions is based on a data-centric architecture, which can offload all network functions from the CPU to the network and perform computation in-transit, increasing the system’s efficiency. This new architecture enables the “smart” interconnect to support the management and execution of more data algorithms within the network. In effect, users can run algorithms on data as it’s transferred within the system interconnect rather than having to wait for data to reach the CPU. Smart interconnect solutions can now deliver both In-Network Computing and In-Network Memory, representing the industry’s most advanced approach to achieve performance and scalability for AI systems.
The first In-Network Compute capabilities include aggregation and reduction functions that perform integer and floating point operations on data flows at wire speed, enabling efficient data-parallel reduction operations.
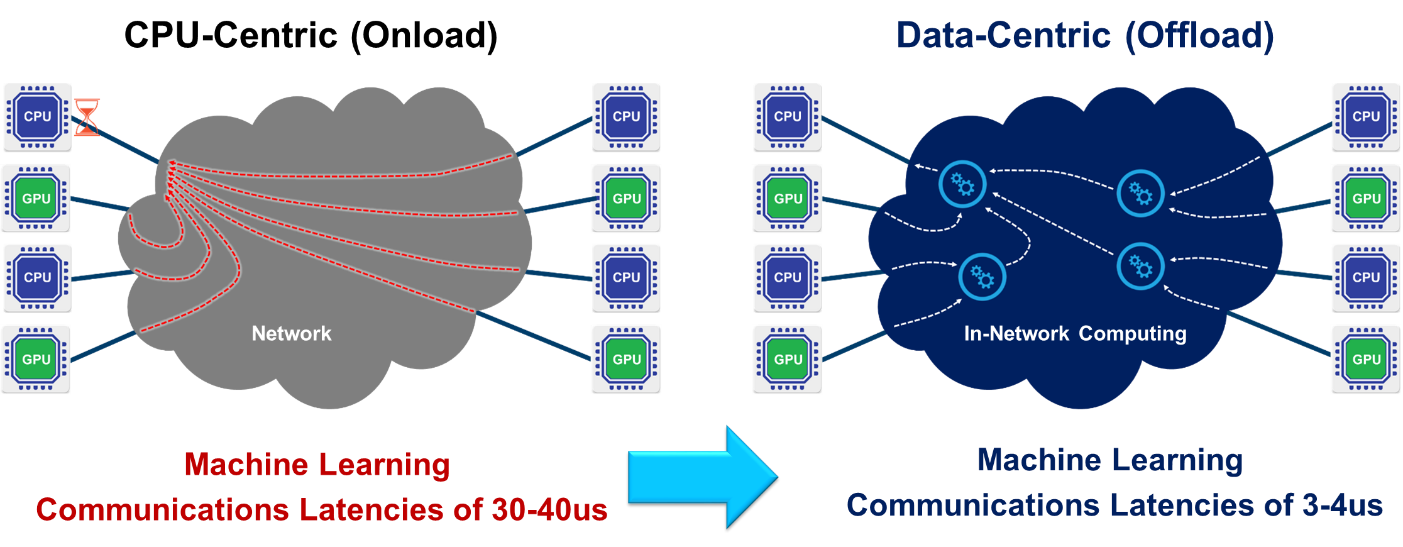 The performance of these data functions has a large effect on the performance and scalability of ML trainings. Smart network protocols can execute in-network data aggregation and reduction operations to dramatically minimize the overall latency of such operations. It also reduces the total cost of a ML platform as it eliminates the need for parameter servers.
The performance of these data functions has a large effect on the performance and scalability of ML trainings. Smart network protocols can execute in-network data aggregation and reduction operations to dramatically minimize the overall latency of such operations. It also reduces the total cost of a ML platform as it eliminates the need for parameter servers.
The ability to perform data reduction and aggregation operations on the network devices at wire speed is the basic component of in-network reduction operation offloading. With such ability, data enters the aggregation tree from its leaves, and makes its way up the tree with data reductions occurring at each aggregation node, with the global aggregate ending up at the root of the tree. This result is distributed in a method that may be independent of the aggregation pattern.
GPUDirect Technology to Enable Fastest GPU–Network Communications
The rapid increase in the performance of graphics hardware, coupled with recent improvements in its programmability, have made graphic accelerators a compelling platform for computationally-demanding tasks in a wide variety of application domains. GPU-based clusters are used to perform compute-intensive tasks. Since GPUs provide high core count and floating point operations capabilities, high-speed networking is required to connect between the platforms in order to provide high throughput and the lowest latency for GPU-network-GPU communications.
The main performance issue with deploying platforms consisting of multiple GPU nodes has involved the interaction between the GPUs, or the GPU-network-GPU communication model. Prior to GPUDirect technology, any communication between GPUs had to involve the host processor and required buffer copies of data via the system memory.
 GPUDirect enables direct communications between GPUs over the network
GPUDirect enables direct communications between GPUs over the network
GPUDirect is a technology implemented within both RDMA adapters and GPUs that enables a direct path for data exchange between the GPU and the high-speed interconnect using standard features of PCI Express. GPUDirect provides significant improvement of an order of magnitude, for both communication bandwidth and communication latency between GPU devices of different cluster nodes, and completely offloads the CPU from involvement, making network communication very efficient between GPUs.
GPUDirect technology has moved through several enhancements since introduced, and the recent GPUDirect version is 3.0, also called GPUDirect RDMA. GPUDirect 4.0 or GPUDirect ASYNC is planned to be introduced in the near future. Beyond the data path offloads of GPUDirect RDMA, GPUDirect ASYNC will also offload the control path between the GPU and the network, further reducing latency operations at an average of 25%.
Remote Direct Memory Access (RDMA) Doubles AI Performance
RDMA usually refers to three features: Remote Direct Memory Access (Remote DMA), asynchronous work queues, and kernel bypass. Remote DMA is the ability of the network adapter to place data directly to the application memory. RDMA is also known as a “one-sided” operation in the sense that the incoming data messages are processed by the adapter without involving the host CPU. Kernel bypass allows user space processes to do fast-path operations directly with the network hardware without involving the kernel. Saving system call overhead is a big advantage, especially for high-performance, latency-sensitive applications, such as ML workloads.
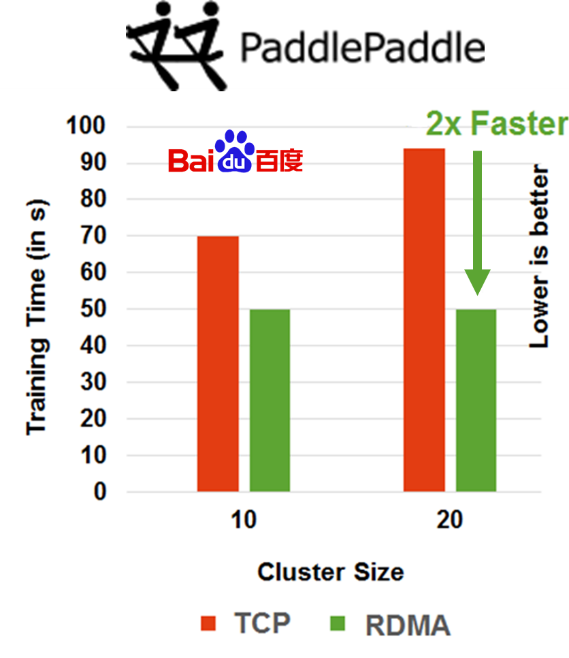
RDMA enables 2X higher performance for PaddlePaddle
While most of the AI software frameworks were designed to use the TCP communication protocol in their early stages of development, now most, if not all (TensorFlow, Caffe-2, Paddle PaddlePaddle and others), include native RDMA communications due to the performance and scalability advantages of the latter.
In-Network Computing Enables AI
To fulfill the promise of AI, the ability to move and analyze greater amounts of data is required for both machine learning training and inferencing processes. The training process is based on using massive amounts of data, requiring the fastest interconnect speeds in addition to new In-Network Computing capabilities. The inferencing process also requires fast data speeds in order to facilitate real-time decision-making for critical tasks, such as providing guidance for self-driving vehicles.
In-Network computing is becoming the de-facto requirement for AI infrastructures. It’s an architecture that relies on RDMA, GPUDirect, NVMe-over-Fabrics (for fast storage access) and smart network protocols to deliver faster data insights and decisions based on new data.
The amount of data required to perform more accurate AI training and facilitate real-time decisions will continue to increase. Demands will only increase for interconnects to provide faster data movement, and, more importantly, to execute data algorithms on the data while being transferred.
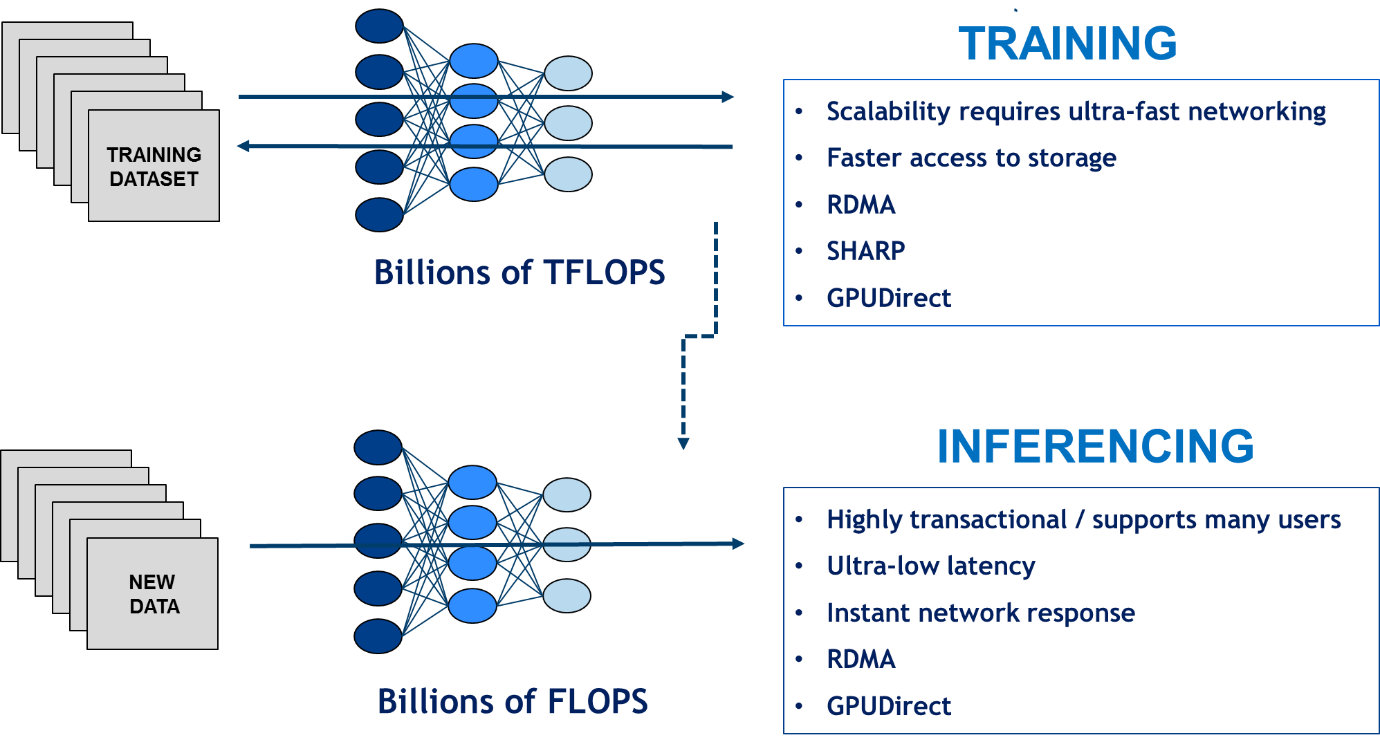 Machine Learning architecture
Machine Learning architecture
As for the interconnect speed, expect to see 200 gigabit per second speeds (server port) in 2018, and 400 gigabit per second speeds in 2019/2020. By 2022, data will move at nearly one terabit per second.
The capabilities of In-Network Computing are set to continue and increase with the future’s ‘Smart’ interconnect generations. Today, In-Network Computing includes network operations, data reduction and aggregation algorithms, and storage operations. Future capabilities may include the complete middleware functions and various parts of the machine learning frameworks.

InfiniBand roadmap plans, NDR expected to deliver 400Gb/s for 4x Link
Gilad Shainer is vice president of marketing at Mellanox Technologies.






