



AI Healthcare Revolution: Doctors and Data Fight Chronic Challenges

Data has been declared the world’s most valuable commodity, the new oil of the global economy, the new gold, the new diamonds and rubies, and this holds particularly true in healthcare, where data and AI are combining to save operational and treatment costs, and – oh yes – lives.
At the recent World Medical Innovation Forum in Boston, AI was the theme, and the opening morning of the conference showcased nearly 20 new AI-based technologies from doctors and researchers (many of them seeking investment funding) at Harvard Medical School, who left the hopeful impression that vital breakthroughs addressing major healthcare challenges are in the offing.
A common element among many of the presented innovations is the amassing of huge stores of medical imaging data from multiple sources so that an individual patient’s X-RAYs, MRIs or other images can be instantly compared with thousands of existing cases, generating a better and quicker diagnosis along with, it’s hoped, the optimal treatment.
Non-Invasive Brain Cancer Diagnosis
Take brain cancer. The most common malignant brain tumors afflicting adults are called gliomas, and there’s no cure, just surgery – for biopsy and, in some cases, removal. Critically important to treatment decisions is the presence or absence of a biomarker (or mutation) called IDH – patients with IDH have a longer survival rate. Today, the only way to determine if IDH is present is to take cancerous tissue from the brain and wait several weeks for biopsy results.
![]() But Dr. Omar Arnaout (neuroscientist and neurosurgeon at Brigham and Women’s Hospital, Boston, and a Harvard Medical School faculty member) is working with a team of doctors and researchers on using deep learning, massive datasets of medical images and patients’ MRI image data to predict IDH status.
But Dr. Omar Arnaout (neuroscientist and neurosurgeon at Brigham and Women’s Hospital, Boston, and a Harvard Medical School faculty member) is working with a team of doctors and researchers on using deep learning, massive datasets of medical images and patients’ MRI image data to predict IDH status.
“You’re constantly weighing the risks and benefits of what you’re doing (for patients) every step of the way, trying to maximize the benefit and reduce the harm, and the more information we have in our hands before going in the better we can do that,” said Arnaout. In blunt terms, this means patients with the good fortune to have IDH are typically better candidates for brain surgery.
The advantage of Arnaout’s approach is that a biopsy isn’t needed to determine IDH status.
“We wanted a non-invasive alternative method with the potential to give us immediate feedback regarding this mutation,” said Arnaout. “If we know (a patient) doesn’t have (IDH) then no matter what we do for him, he’s not going to survive for more than 18 months, then we’re less likely to take on a lot of risk and cause a deficit (in layman’s terms: brain injury) that will put patients in a nursing home for rest of life. But if he has the good mutation and the potential to live for years, then the two of us would be willing to take on a little more risk and potentially cause a deficit that he can go to rehab and get better from.”
Arnaout and the team collected large data sets of MRI images from Brigham and Women’s and other hospitals, along with publicly available data, and labeled them for IDH status. Patient MRI data is then fed into a convolutional neural network with an IDH algorithm with a simple classifier at the end – yes or no for IDH. “We play with different sequences and ways of optimizing it,” Arnaout said, resulting in a trained neural network with IDH prediction accuracy of nearly 90 percent.
Even more encouraging, Arnaout said the project is as a proof-of-concept for a suite of tools using deep learning to predict other brain tumor biomarkers, augmenting traditional radiological interpretation for clinical decision making.
Containing the Spread of ‘Hospital Acquired Infections’
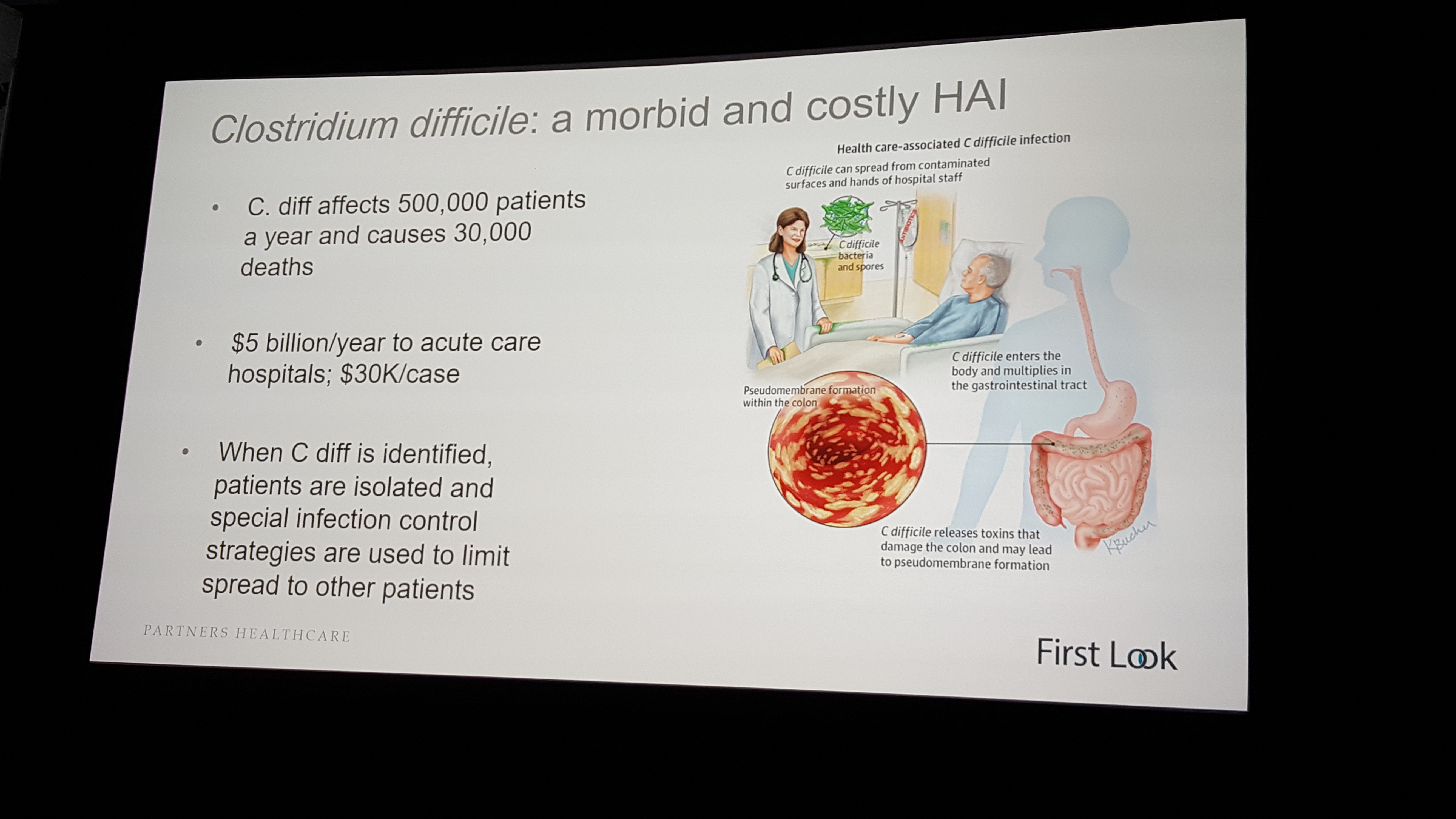
The bitter irony that hospitals are places where people often get sick is lost on no one. A particularly insidious “hospital acquired infection” (HAI) is clostridium difficile, or “C. diff,” a pathogen that infects the gut, is both highly contagious and resistant to many antibiotics, accounts for $5 billion in annual healthcare costs and afflicts half a million people per year, killing 30,000.
Dr. Erica Shenoy, associate chief, Infection Control Unit, at Massachusetts General Hospital (MGH) and Harvard Medical School assistant professor, is working with a team from MGH, MIT and the University of Michigan to develop a predictive, machine learning-based model that identifies key risk factors – i.e., locations in the healthcare facility where C. diff transmission is most likely to happen – within a given hospital, healthcare clinic or nursing home.
The project’s twin objectives: earlier diagnosis of C. diff and transmission prevention.
“Despite substantial efforts to prevent C. difficile infection and to institute early treatment upon diagnosis, rates of infection continue to increase,” said Shenoy. She displayed a slide with a seemingly random mass of dots superimposed over an image of a hospital floor plan.
“Each dot is a patient, whether we’ve diagnosed them or not for an infection, and these are connections between the points, shared spaces, shared procedures, shared providers,” she said. “These are complicated connections. And for diseases that get transmitted through the environment, through the hands of healthcare workers, understanding these connections, these edges, is so critically important because if we break those edges and connections, we can stop the spread of disease.”
Doctors and healthcare workers can spread C. diff even if they follow hygiene rules. “If (a nurse) washed her hands, which she’s supposed to do,” said Shenoy, “she can still transmit disease because there could be C. diff on the bed rail she’s touching, so when she shakes the patient’s hand, the patient can then ingest the C. diff.”
 Previous efforts to model C. diff transmission used a small number of variables, according to Shenoy, and utilized a one-size-fits-all approach. What’s needed, she said, is much more data. “…more effective risk stratification models can be constructed using machine learning techniques applied to large sets of covariates (features) drawn directly from the electronic health record (EHR),” she stated. “These models leverage rich temporal signals that arise from high-dimensional time-series data, boosting discriminative power.”
Previous efforts to model C. diff transmission used a small number of variables, according to Shenoy, and utilized a one-size-fits-all approach. What’s needed, she said, is much more data. “…more effective risk stratification models can be constructed using machine learning techniques applied to large sets of covariates (features) drawn directly from the electronic health record (EHR),” she stated. “These models leverage rich temporal signals that arise from high-dimensional time-series data, boosting discriminative power.”
And the model needs to be customized to each healthcare facility and its own particular high-risk points and connections where disease transmission takes place.
Shenoy and the research team has validated a C. diff risk prediction model based on the EHRs of 250,000 patients.
“We extracted patient demographics, admission details, patient history and daily hospitalization details, resulting in thousands of features, and then used these features to build predictive models,” she said. “…We’ve taken every single patient that’s in the hospital today, and rank them according to increased risk, so we can focus our interventions on the highest risk patients.”
The result: the models on average identified patients five days earlier than clinical diagnosis.
“If we’re able to move (C. diff detection) back a day, two days, five days,” said Shenoy, “what we do is not only diagnose patients earlier and give them better, earlier treatments, but we isolate those patients and prevent them from becoming a source of more infections in a hospital.”
According to MGH, the research team has made the algorithm code freely available for others to review and adapt for their individual institutions. Shenoy said facilities that explore applying similar algorithms to their institutions will need to assemble the appropriate local subject-matter experts to validate the performance of the models in their institutions.
Early Diagnosis of COPD
Chronic obstructive pulmonary disease (COPD), primarily caused by smoking (there are still 42 million smokers in the U.S.) is the third leading cause of death in this country, affecting 22 million Americans, and accounting for $32 billion in healthcare costs. It’s also associated with various “co-morbidities,” including cardiovascular disease, musculoskeletal disorders and lung cancer. Despite this notoriety, COPD remains widely underdiagnosed.
Dr. Raúl San José Estépar (co-director, Applied Chest Imaging Lab at Brigham and Women’s and associate profession of radiology at Harvard Medical School) argues that COPD remains underdiagnosed – it’s a “heavily latent problem,” he said – in part because medical images that could reveal it are underutilized. His goal is to leverage and analyze image data from the 80 million CT scans and X-rays (CXR), two-thirds of which are of the chest, done annually in the U.S.
Estépar’s idea is to enable earlier COPD diagnosis in part by mining standardized Picture Archiving and Communications Systems (PACS), a data warehouse containing millions of CT and X-ray images, “which provide a unique snapshot of patients’ health status that includes three major systems: heart, lung and skeletal muscle.
“The PACS provides a beautiful, holistic view of the patient at the moment of the scan,” he said. “That means the image might reveal other conditions because they’re subclinical, they’re not reported and might reveal co-morbidities. So I think there’s an opportunity to exploit that information, take that information out of the imaging to identify risk that might be a potential problem in the future.”
Estépar and his team have developed image-based AI approaches for COPD patient risk assessment.
“Our risk models are based on deep learning approaches to quantify emphysema, air trapping, heart size, body composition and bone mineral density from both CT and CXR images,” Estépar said, adding that the team also has developed prognostication models based on “canonical landmark” view of CT scan that can “stage and prognosticate acute respiratory event and death in COPD.”
“We’ve developed technology to do high throughput retrieval of CT images in a PACS. We’ve also developed technology to do automated annotation of those images, that’s enabling us to develop technologies for disease detection, not only COPD … but also disease detection for event prediction.”
Slow Adoption of New Treatments
For all the education and training that clinicians undergo, for all the peer-reviewed articles about diseases published in medical journals, and for all the healthcare conferences at which doctors convene and share new findings and new treatments, it’s shocking to learn that translation of evidence-based medicine into clinical practice is delayed by an average of 17 years.
But this, according to Dr. Maulik Majmudar, (associate director at Massachusetts General Hospital’s Healthcare Transformation Lab and assistant professor of cardiology at Harvard Medical School), is the way things are today.
 “Despite the (medical) progress we’ve made over the past century, there’s a tremendous amount of scientific uncertainty in the practice of clinical medicine,” Majmudar said, citing studies finding only about 20 percent of all medical decisions are based in practical realities, and a Rand Corporation study concluding that about half of medical decisions are wrong or sub-optimal.
“Despite the (medical) progress we’ve made over the past century, there’s a tremendous amount of scientific uncertainty in the practice of clinical medicine,” Majmudar said, citing studies finding only about 20 percent of all medical decisions are based in practical realities, and a Rand Corporation study concluding that about half of medical decisions are wrong or sub-optimal.
Majmudar said there are several reasons for the gap between medical progress and practice.
“There’s no point-of-care tool to assess this quality gap,” he said. “So the unmet need we’re trying to address is the lack of access to aggregated and actionable patient data, as well as insights into variations in care delivery, both of which we think can significantly aid to identify the gaps in quality and, hopefully, inform clinical decisions at the point of care in the hospital.”
Majmudar is part of team developing SmartRx, a natural language processing (NLP) software platform that enables real-time querying of the entire electronic health record for patients that have had similar symptoms – or, in medical terminology, “”for specific patient cohorts with targeted inclusion and exclusion criteria.”
The aim is to build a platform that measures gaps in quality of care at an individual and population levels and to close the evidence-practice gap. SmartRx is designed to leverage historic data around practice-based medicine to drive clinical decision making and “evidence generation” in cases where scientific uncertainty exists.
“One has to wonder why we don’t leverage our past experiences collectively to inform future clinical decisions,” Majmudar said. “SmartRx is a software engine that enables customizable, real-time, semi-automated querying of the electronic health record. A key step is using MLP to understand not just the context but extract information from both structured and unstructured fields, including (doctor’s) progress notes, procedural reports, demographic information, laboratory data, medications, outcomes results and mortality data, to make such information visible and actionable.”
Majmudar said SmartRx has been built to be easy to use, including the use of data visualization dashboards, to promote adoption by clinicians. And it’s ultimate goal is to deliver a “learning health system,” in which "science, informatics, incentives and culture are aligned for continuous improvement and innovation, with best practices seamless embedded in the delivery process and new knowledge captured as an integral by-product of the delivery experience.”






